|
OntologyStream Inc Briefing & Elementary Tutorial on
categoricalAbstraction (cA) August 2, 2002 |
|

Behavioral Computational
Neuroscience Group (BCNGroup)
provides
independent feasibility studies of knowledge system integration
processes. The Group has a ten-year history.
In 2001 and 2002, the general concept of a Knowledge Operating System (KOS) was proposed and in this context we describe how human-community communication characteristics might be transformed into semi-structured economics based on knowledge sharing.
The BCNGroup believes that research on
the
deployment of KOS systems is evolving into applied knowledge science. Tools are being developed to fit specific
community needs. The KOS development
environment is currently available under a site license at $19,500.
Training in KOS design and standards is
available
from The OntologyStream. BCNGroup
individual membership, and corporate sponsorship program information,
is
available from the web page, www.bcngroup.org.
This tutorial is on what some regard as a deconstruction of the mathematics and technology of text and data indexing. The result is deemed a type of Synthetic Perception about the invariance in data and the development of human annotation of what humans regard as meaningful. Synthetic Perception is seen as a by-pass of current data-mining and text-indexing methods
Copyright 2002, The OntologyStream Inc
Philosophical
Overview:
Our Knowledge Management (KM) problems stem from past KM
methodologies. Currently, communities
attempt to improve knowledge sharing practices by contracting for new
computer
technologies.
In the first step of a knowledge technology deployment one objectively evaluates proposed technology and methodology and develops an understanding of what is available in the marketplace. One must know what is available in computer systems and from innovations in various supporting communities.
A bottom line is that the human experience of knowledge be shared. At core this is the nature of human communication. A disinterested third party cannot have a vested economic interest, particularly one that is controlling of all other interests. The community at large loses. Society loses.
Only in an economically unencumbered environment can one expect that concept base indexing and the propagation of knowledge be accomplished. The compensation for knowledge sharing has to be accrued to the individuals who are sharing this knowledge.
The tutorial will provide a full disclosure of a fundamental discovery of categorical abstraction and the inventions of stratified theory in the context of knowledge technologies.
Due to the
2001 War on Terrorism, the government is prepared to
scale up IT support for homeland security.
The problem is in the capture and management of meaning and the
inability to extract meaning using purely computational means. In a knowledge war, our conventional IT
'weapons' are weak. In theory, they
could be much stronger.
One must look
to natural science and shift from word-based
indexing to concept-based indexing.
Natural scientists surmise that a concept can be identified and
processed directly, and with revolutionary effects. But
it is not a simple matter to bring this principle into full
application.
The situation
is analogous to World War II. Scientists
surmised that munitions are much
stronger if they were based on a completely different principle -- a
nuclear
reaction rather than a chemical reaction.
The Manhattan Project acted on that theory. Later
peaceful uses of nuclear power where developed.
We propose a
new Manhattan Project for Knowledge Technology
(KT) that will give the Nation a decisive tool in the knowledge war. As the War is won, we expect to see human
productivity increase while the National leads the World in addressing
the root
causes of this unfortunate war.
What we
propose is a project that allows leading scientists to
concentrate on the problem and allows engineers to bring the solution
to
fruition. It requires stripping away
some of the institutional impediments that have been retarding this
development.
Initial Work Outline: Any “conceptual space” associated a knowledge system can be mapped following these steps.
1) The map is produced by collecting together between 100 and 200 samples of the description of technologies, theories and frameworks (using web searches and in house materials).
2) Once this sample is available as a text collection, we write a simple parser to produce a categorical abstraction input file (datawh.txt) that is discussed in the tutorial.
3) The OSI Knowledge Operating System (OSI KOS) is used to record human perceptions about the structure in this input file and render topic maps (XML) for inspection and comment.
The mapping process, of course, has various levels of resolution. OntologyStream Inc develops a broad and definitive model of the IP (Intellectual Property) and conceptual space that surrounds” the basic sub concepts of all knowledge system technology. This work is preparatory for
1) The full mapping of all conceptual themes related to the knowledge system’s subconcepts in both the US PTO database and in the Internet public literature.
2) The production of dedicated patents covering the work of those developing the deployment plan and observing the progress in the deployment.
3) Informed decisions over technology acquisition during integration.
The BCNGroup Charter defines a science-based Intellectual Property management structure that serves the community of innovators supporting the knowledge technologies.
This management structure is designed to serve business partners as well as innovation processes, and is the basis for coordinated development of knowledge technology and knowledge science.
System description
Knowledge
Operating System (KOS) can be used to track global trends and
anticipate events.
The system brings together a variety of innovative components to
provide an
"intelligence-vetting engine" that globally tracks emerging events
related to any topic or event type. The
necessary condition for seeing the event is that a sensor must produce
data
structure indicative of the event.
Categorical Abstraction bypasses the complexity issue in massive
data
sources by replacing massive data with a very much smaller set of
categories. The categories can be used to
retrieve all
of the data that will produce individual categories, so we have a true
"compression" of data into information... and the compression may be
as much as a million to one. Novelty detection falls out of this
process since
a single occurrence of a data element will appear as a new category if
such a
data element is in fact novel. Event chemistry opens this cA
substructure into
a biologically feasible information routing and retrieval architecture
based on
the Prueitt tri-level architecture { memory, awareness, anticipation }.
Machine inference and situational simulation
as well as sense making is enabled
Collection – KOS will automatically monitor information flow in the Internet on a 24/7 basis, looking for new items that are related to the subject and events of interest. KOS software agents look for new and novel relationships not previously anticipated and send data structures into centralized information vetting areas staffed by humans.
For example, all Internet published scientific conferences in a specific area of interest might be mined to produce trend analysis of intellectual property. Concept mining in KOS is language-independent.
Annotation - Human annotation of trends can be done in one’s native language and incorporated into a single, multi-language knowledge base. (By avoiding translation of any inputs, meaning is preserved and the significant costs and delays of translation are avoided.) Topic maps in any language are constructed using the OASIS standard.
Storage - Our collected information is stored in formats that allow an object to be directly related (“structurally coupled”) to any other object. The relating structures are independent second order control mechanisms that support query, routing, and anticipatory responses.
A tri-level architecture is used that separates: (1) known events, (2) categorical abstractions (cA), and (3) aggregations of categorical abstractions (event chemistry or eC) under the constraints of a knowledge base.
Extraction - A number of mature technologies extract information from data sources. This information is diffused into a substructure layer (cA) of information that serves the agile reconstruction of information in context (eC). The agile technology allows us to look at an object of investigation from many different perspectives.
The extraction process is represented as categorical invariance in the patterns of word expressions and processed into a central, sparse knowledge base. Information compression, routing and inference processes are achieved using a technique (I-RIB) that renders visually as graph structures expressing structural relationship and in auditory form.
Interaction with analysts - A number of analytical tools automatically develop ontologies and taxonomies. KOS logical and structural relationships are rendered visually or optionally with sounds. The overall structure of a given area of knowledge is rendered visually. Various scenarios are generated and humans are assisted in exploring variations in strategies and in storing work product related to these investigations. The system itself can be used to analyze analyst performance.
Simulation and sense making – In KOS, the cognitive load is allocated to the human. The conventional approach, of formal deduction or computational expert systems, is replaced with an extension of quasi-axiomatic theory coupled with human experience within the KOS visual and auditory environment and within the community of KOS analysts.
What-if scenarios and conjectures about causes take a new form where humans in small communities develop meaning in dialog about KOS-defined event structures.
Display – KOS provides breakthrough capabilities for identifying and monitoring early indicators of significant change. Visualization of the categories of data and relationship among these data enhance the ability of analysts to anticipate emerging events.
Tutorial
The remainder of this briefing will provide a precise discussion of our methodology, including the OSI categoricalAbstraction (cA) engine and event Chemistry (eC) engines. We start with a download of software at
www.ontologystream.com/cA/tutorials/download/Elementary.zip
which is 298K in a WinZip file and 1 Meg when unzipped.
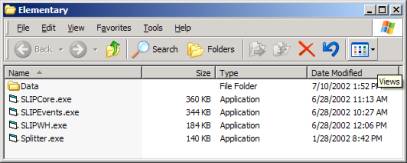
Figure 1: The unzipped file for this tutorial
The tutorial Data folder starts only with a small file called datawh.txt containing the following text:
IPaddress eventType
109 E1
110 E1
101 E2
101 E3
109 E4
105 E3
105 E2
106 E3
107 E3
102 E5
103 E6
104 E5
108 E1
109 E3
We will not use the Splitter.exe in this tutorial.

Figure 2: The SLIP conjecture with atoms = IPaddress
Open SLIPWH.exe and type in “a = 0” and then “b = 1” in the command line to produce the link conjecture seen in Figure 2. There are spaces around the “=” sign in these commands. Type “Help” to see the list of knowledge operating system (KOS) verbs available from here. Call 703-981-2676 to ask a question.
Now issue the KOS commands “pull” and “export”. Again, the command “Help” will give more information about the KOS commands.
Close the SLIPWH.exe and look into the Data folder. You will find:
- Conjecture.txt
- Links.txt
- Mart.txt
- Paired.txt
You should open each one and see if you understand how each was created and what each of these data structures may be used for.
Links.txt contains
101 E2 E3
102 E5
103 E6
104 E5
105 E2 E3
106 E3
107 E3
108 E1
109 E1 E3 E4
110 E1
The first line in
Links.txt indicates that the address 101 has been associated with E2
and E3 by the SLIP conjecture.
It is important to note that two things have happened up to this point. First some process created the original datawh.txt. The second thing that has happened is that the SLIP conjecture is used as a conjectural convolution over this datawh.txt file. There are many ways to create the datawh.txt files and many ways to create conjectural convolutions. But we are taking a simple example. The process that produces the datawh.txt file is completely up to the user of the OSI browsers. However, at this point the OSI software only offers the simplest of the convolutions based on simple link analysis.
Paired.txt contains:
101**105
101**105
101**106
101**107
101**109
102**104
105**106
105**107
105**109
106**107
106**109
107**109
108**109
108**110
109**110
These are pairs of elements from the column that was selected to produce atoms. The nine unique elements that are either first or second position in these pairs is the set:
{ 101, 102, 104, 105, 106, 106, 108, 109, 110 }
103 is not in this list because E6 occurs only once in the eventType column and so there is never a fulfillment of the SLIP conjecture that involves 103. The generalization to the class of convolution operators might be anticipated by how the SLIP conjecture produces atoms based on finding all instances where the conjecture holds true.
One way to generalize this is to use Frank Schank type frames with slots and fillers. Atoms are then things that are found to occupy slots.
Now open the browser SLIPCore.exe and issue the KOS commands “import” and “extract” to produce the screen in Figure 3a. Click once (not twice) on the A1 node to produce the scattering of the atoms.
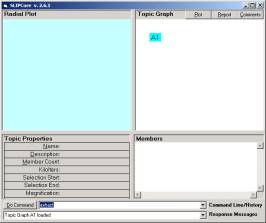

a b
Figure 3. The Core Browser (a) before clicking on the A1 node and (b) after
The nine atoms in the set of “all” atoms is scattered onto the surface of a two dimensional sphere. (This is generalized to allow “dimensions of information processing” to n dimensional spheres.)
The clustering on the sphere is similar to a Kohonen feature extraction algorithm (artificial neural network) but is simpler and may be more powerful. The clustering algorithm is a form of scatter-gather techniques that have been used in the text understanding research field for perhaps two decades. However, the way that the scatter-gather is done is unique to Prueitt’s work and is simpler and more powerful.
The technique itself has one additional innovation based on the conversion of the ASCII into a line in number base 64. This conversion allows one to very quickly answer a set membership question. This question is about whether or not a pair randomly selected from the set of all possible pairs of atoms is in the set of pairs in Pairs.txt. There are 9 atoms in this case, so there are a possible 81 pairs that can be produced.
The Pairs.txt file has 15 members. In this case the set membership problem is easy. A random pair has a probability of 15/81 of being in the Pair.txt file.
However we have data sets that contain 10,000 members. In this data the set of possible pairs is greater than 10,000,000. In this data set the atoms are ASCII stings that have between 10 and 40 characters. This means that the membership question requires that a string match be made between a text string of between 20 and 80 characters and a string of ASCII that is 10,000*80 = 800,000 characters long.
The critical computational requirement is this membership question, and database solutions are far to slow. We need to resolve 10 million membership questions to complete the average scatter gather task.
This membership question can be addressed in many ways, but perhaps the most optimal way is to pad out each of the 10,000 members to have a length equal to the maximum length over the entire set, say 80 characters and map this to memory.
One needs less than one Meg of memory to accomplish this task. Then the set membership question can be answered in less than 20 fetches (the contents of one of the 80 character data “cell”), compare (the contents of the cell to the pair that one is asking the membership question of.) steps! Why? (The answer is not proprietary; it is just best to figure this out for oneself. Hint: 2^20 > 800,000)
The scatter-gather requires that this single membership question be asked and answered perhaps 10,000,000 times. This required about four hours in FoxPro in our early studies. However, when we used the In-Memory map we find that this take less than 30 seconds.
It has been a few months since Prueitt saw this resolution of the membership question, and he has developed a few other approaches to this, but each of these other approaches are slower than the algorithm suggested above.
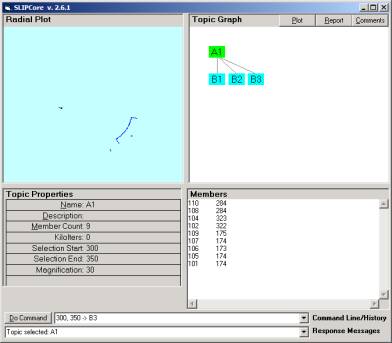
Figure 4: Creating subcategories
Moving
on to the clustered data.
By clustering the data in the tutorial set we find that there are three clusters. Type in “random” in the command line of the Core Browser, and then type in “cluster” to see the clusters form. The three clusters can be moved into subgroups by using a command
“a, b -> categoryName”
as done is Figure 4.
See the text in the Command Line in Figure 4, and perhaps type Help into the command line.
The clustering process in the scatter gather is fast and finds a unique decomposition of the elements from the bag of atoms into a set of categorical primitives, such as seen in the next figure where the size of the set of atoms is 2395.
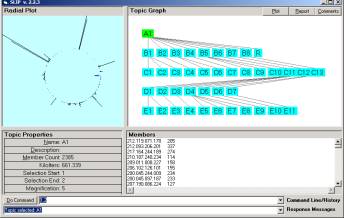
Figure 5: From http://www.ontologystream.com/cA/papers/EventDetection.htm
However, in our case we have only three categorical primitives (called stratified primes).
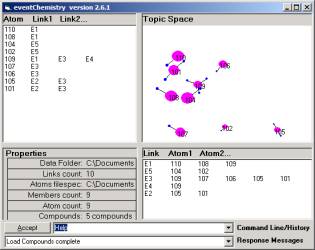
Figure 6: We have 6 simple compounds each developed by a single link and 9 atoms
These
three primes are composed of five simple compounds (each
defined by one link) and the nine atoms.
On can see this by double clicking on the A1 node to produce the
screen
in Figure 6 (the KOS browsers have four re-sizable windows and you can
readjust
your sizes.
Then
close the browser and the software remember the previous
settings.)


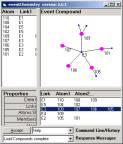


Figure 7: The five simple compounds
Now we can alter the datawh.txt file so that one gains a better intuition about what is possible with cA and eventChemistry.
Close all of the KOS browsers. And put the folder (Figure 1) on the desktop. Make a copy and name it what ever you wish. Having both on the desktop and no programs running is helpful. Now go into the Data fold of the copy and delete all of the files and the folders in the data folder except the datawh.txt file. Open this file up and add a new line:
105 E4
Be sure to put one tab between “105” and “E4”. Now repeat the steps to produce a set of atoms. You will get the new categorical Abstraction seen in Figure 8:
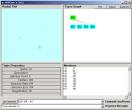
Figure 8: The categorization with the new data element added to datawh.txt
The new compounds are given in Figure 9.

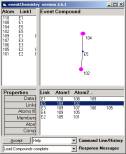



Figure 9: The updated compounds
Second
Change
to datawh.txt
Now make a third copy of the folder and delete all of the data except of the datawh.txt file again. Take all but the first line and copy in several times into the same file (not introducing blank lines.) Now redevelop the cA and eventChemistry. You will find that the Core Browser will have the exact same data.
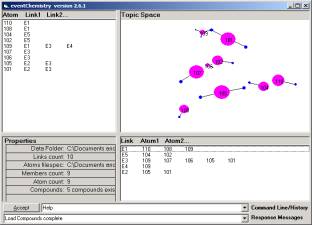
Figure 10: The cA and eventChemistry after adding duplicate data
This is a property of the fact that all categories are already present before the additional data is added. The additional data is not introducing any new categories. One can compare Figure 10 to Figure 6 and see that everything is the same.
Root_KOS
(root Knowledge Operating Systems) Overview
Root_KOS
loads and saves tabular files to/from memory, and responds to
scripted commands.
Loading
and saving tabular files is important because SLIP Browsers
work with data that is in a system file or in a special In-Memory
Referential
Information Base (I-RIB) data structure.
The SLIP Warehouse and SLIP Technology Browsers transform data
that
resides on text files. (See Figure 1).
Both depend on a Root_KOS kernel.

Figure 11: KOS Browsers work
together
The
Warehouse Browser takes any tab delineated audit
log and
quickly produces a data mart and a combinatoric expression of link
analysis
within the values of an event log. Both
of these files are produced using In-Memory Referential Information
Base
techniques. Once the files are produced
then the Technology Browser can use them.
The
Technology Browser uses In-Memory RIB techniques
to develop
event detection. The Event Browser
(currently underdevelopment) is launched from the Technology Browser
and some
data resources are exchanged. SLIP
atoms are identified in the Technology Browser and those atoms involved
in an
event are conveyed to the Event Browser.
The
I-RIB uses system files, memory maps and mathematical objects such
as lines and arrays. OSI’s I-RIB
technology is derivative of mathematical formalism called structural
holonomy.
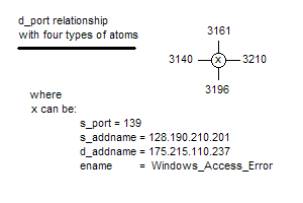
Figure 12: Some early event
chemistry drawings
Structural
holonomy is the innovation of Paul Prueitt and is based on
his interpretation of the work of renowned neuroscientist Karl Pribram. This formalism is of the nature of
mathematics and yet has grounding in experimental literatures from
biology and
neuroscience. The basic work has been
privately peer reviewed from over a decade.
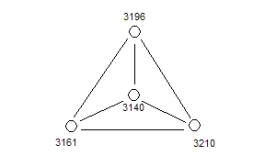
Figure 13: One
of the early event compounds
The
underlying concepts of structural holonomy is being made public
domain in order to facilitate the development of I-RIB systems in
support of
knowledge technologies that depend on very fast data aggregation
methods.
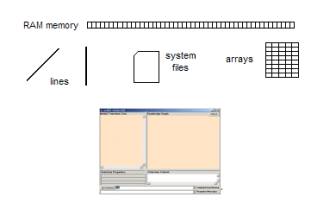
Figure 14: The Root_KOS User
Interface and data structures
OSI’s
I-RIB technology is a full data base management system that is
designed to minimally cover the requirements of many classes of data
aggregation, artificial neural network, evolutionary programming and
data
warehousing systems. The smallest
version of the I-RIB technology is part of the 172K SLIP Warehouse and
the 348K
SLIP Technology Browser. Both of these
systems are operational.
The
Root_KOS is marketing as a development environment, complete with a
minimal I-RIB system. Yearly site
license is $19,500 for the development environment. Root_KOS
is applicable to elementary research in Natural Language
Processing, full text mining and warehouses, and certain types of
eBusiness
functions. The development of
deployable applications are streamlined.
Any
KOS Browser can recognize scripted commands by (1) command line
input (2) certain mouse events on nodes of arcs in the graph window, or
(3)
mouse events on the node tabs at the top of the graph window. The exit
and help
functions are the most basic of all scripted commands.
Scripting
provides for user gestures as response to the presentation of
state information from an internal ontology or finite state machine. Algorithmic responses to a human gesture
produce changes in
1)
The ontology or
finite state machine,
2)
Changes in
auxiliary resources such as system files and
3)
A textual
response in the response line and/or a sound response.
KOS
Browsers have:
A.1:
Modal transforms that switch the view in display areas and
change the
system’s response to script commands
A.2:
Graphs that are generated from a process model. The
elements of the graph are active
objects.
A.3:
Allow the selection and movement of objects within the graph.
A.4:
Selection and movement will change the state of corresponding
ontologies
or finite state machines.
A.5:
Selected objects will refer to contents. So
for example, selecting a node and typing “Open Event Browser”
(or “oeb”) will take the contents of the node and move this content to
a new
instance of the Event Browser.
Selecting a node and typing cluster” (or “c”) will cluster the
atoms
corresponding to that node.
A.6: Grammatical
interface composed of a command/response line with history.
KOS
Browsers have a formal Program Interface (PI) that is completely
implemented through a categorized message stream interface. The machinery for the PI is complete in the
Root_KOS and extendable in any KOS Browser.
Project plumbing in
the root KOS
provides maximal notational affordance by using extensible graph based
formalism.
Notation on states and gestures extend the KOS foundational notion: The notation for states, gestures and locations is:
The
set
of world states S = { sj }.
The
set
of gestures G = { gi }.
The
set
of locations L = { Lk
}.
A formal theory of states and
gestures provide a computational means to discuss event paths in human
computer
interactions, particularly for telelearning, distance learning, and
virtual knowledge
collaboration. These states can be used as part of the mechanics of
what we
call a "knowledge processor".
The notion of location allows for
the development of enterprise KOS.
The formal theory of states and
gestures is built from a precise formalization of computer game and
user
interactions in Multiple User Domains (MUDs) (such as the Palace 2-D
chat
environment) and Role-Playing Games (RPG) (such as ChronoTrigger or
Zelda.)
Gestures and states can be modeled
as the fundamental units of a specific finite state machine. Thus,
under any
such designation, the related model of event sequences is computable. The KOS, however, must represent the
invariance in the data AND the mental states of humans.
This means that our effort to representation
the contents of mental events within the context of discourse, should
be split
into two parts. These two parts are
1)
The
aggregation of data invariance and
2)
The
representation of user response history in terms of the set of
aggregated
invariance.
The aggregation of invariance is
used to represent the computer processes, and the user response history
is used
to represent the natural world. The
communication between finite state machines is used to control and
allow user
(community) focus on a specific set of issues.
This control of focus provides universal “Informational
Transparency
with Selective Attention”.
We can assume that a set of states, S = { sj
},
are created before hand and the gestures G = { gi } are a
set of
stored responses. This would mean that S and G are actually the atoms
of finite
state machine. However, the existence of event states may be actually
implicit
unless actually instantiated as part of an event. In this case, it is
proper to
refer to S and G as virtual finite state machines. In
the course of working with the KOS Browsers, users select
gestures in response to a presented state from the computer. This
pairing of
state and gesture is a represented as a mutual decision event.
In the Event Chemistry being developed by OSI,
the finite
state machine is a virtual combinatoric expression of the aggregation
of
abstractions called “SLIP atoms”. This
abstraction plays a role similar to the abstractions we have in
physical
chemistry. Each atom has a specific set
of linkage potential. The manipulation
of the linkage potential (called “valence: in physical chemistry) leads
to the
formation of chemical compounds.
The notions of an “atom” and “chemical valence”
are useful
abstractions. In the Event Browser we
use a different set of abstractions to visualize the parts of events
and the
means that these parts have to be a compound in a larger event.
Figure 15:
event
chemistry
An abstraction from the signatures of real
occurrences leads
to event chemistry. We have developed an additional
capability. This capacity is to provide a unique situational analysis
based on
the relationship of part to whole as revealed in the formal literature
of
Russian applied semiotics and related literature in the West.
Definition: The term
formal system refers to a four-term expression:
M = < T, P, A, R>
where T = set of basic elements, P
= syntactic rules, A = set of axioms, and R = semantic rules. The interested reader can refer to Situational
Control for a more detailed treatment of formal systems.
For our purposes we need only
refer to a figure from page 37.

Figure 16: Taken from Pospelov Situational
Control
In figure 16, the set of base
elements T are combined in various ways to produce three types of sets,
axioms,
semantically correct aggregates, and syntactically correct aggregates.
We
should remember that mathematical logic is founded on a similar
construction
and therefore that most of the results of mathematical logic will
somehow apply
later on to the theory of knowledge processing that we are
constructing. For
example, the set of axioms can be specified to consist of independent,
non
contradictory and self evident statements about the set of base
elements T.
The axioms are our analog to the
quantum mechanical substrate that gives rise to the mechanisms that in
turn
produce some of the material and energetic constraints that are
involved in the
creation of awareness. Rules of inference can also be formulated to
maintain
notions about true or false inference from assignments of a measure of
truth to
the axioms.
The set of syntactically correct
aggregations of elements of base elements can be defined either by
listing or
by some implicit set of rules.
The semantically correct
aggregations could then be interpreted as those syntactically correct
aggregations that have an assignment of true as a consequence of the
inference
rules.