A Bead Game was developed
from this Document
Strategy for
organizing text data
Using CCG plus other
techniques
November 14, 2000
Computer Cognitive Graphics (CCG) is a technique developed by Alexander Zenkin. The technique uses a transformation of sequence values into a rectangular grid. Visual acuity is then used to identify theorems in the domain of number theory.
Our purpose is to generalize this work and to integrate the components of CCG technique with knowledge discovery methods more widely used for automating the discovery of semantically rich interpretations of text.
An application of knowledge discovery in text will be developed as a parse of text in the context of intellectual property mining. TelArt Inc. has a client that wishes to review this application. Applications to intelligence vetting will be clearly indicated in our final report to Army Research Lab (Due in late December.) However, the immediate application of new methodologies to intelligence vetting is left for a future project.
Test Corpus: We have a test corpus of 6,000 one-paragraph descriptions of patents. This corpus is the property of our commercial client. The client has made the collection available to TelArt for evaluation exercises involving several methods, one of which is the CCG generalization.
The interpretation of text is oriented towards retrieval of similar text units, the routing of text units into categories and the projection of inference about the consequences of meaning.
TelArt Inc. expects receipt of a behavioral criterion from our commercial clients regarding proper evaluation of Latent Semantic Indexing, CCG - derived and other informational indexing systems. This criterion will likely be proprietary in nature.
The movement from one domain to another will produce a variation of behavioral criterion. Thus client criterion can be generalized to fit many other domains outside the domain of content evaluation. Behavioral criterion for intelligence vetting is an interest to TelArt Inc.
Technical Aside
Locally, the clustered tokens on a number line can be rough partitioned using neighborhoods (see Figure 1)
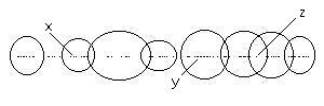
The circles in Figure 1 indicate boundaries of categories. These categories overlap. We can map the categories to a n dimensional space. In this case n = 8.
x --> (0,1,0,0,0,0,0,0) or (0,0.7,0,0,0,0,0,0)
y --> (0,0,0,0,1,0,0,0) or (0,0,0,0,0.6,0,0,0)
z --> (0,0,0,0,0,1,1,0) or (0,0,0,0,0,0.3,0.2,0)
Where the first representation is a Boolean representation of inclusion and the second representation measures show a degree of closeness to the center of the distribution.
The question of how to assign category memberships to new text elements is addressed in the tri-level routing and retrieval architecture and voting procedure as well as in Russian Quasi Axiomatic Theory.
Problem Domains
There are some important and general problems in automated recognition of patterns in data streams. In some cases, the stream may be regarded as a stream of text. The text can then be converted or transformed into tokens that have been shaped by linguistic and semantic considerations.
The development of an information base from a text database is at least a three step process:
1) the transformation from text to tokens,
2) the shaping of token identification, and
3) the development of relationships between tokens
For example, an illness might be recognized from a written description of symptoms. The text of the descriptions can be converted to number sequences.
The first step is to randomize the location of numbers by a uniform projection into a line segment. The projected numbers become tokens for the text units. The nearness of tokens on the number line is discarded. Some transformations might then be applied to produce clusters of values around prototypes of concepts that are expressed in the text (in theory).
CCG images can be involved in a visualization of these prototypes. The clusters, once identified can be used in the definition of a tri-level category policy to be used to place next text elements within an assignment relative to these categories. Prueitt invented this tri-level architecture during the period 1996 – 98.
Some Uncertainties
The objective of our study is to see if we can find a representational schema, transformation of topologies, and some relationship that becomes clear as some process of analysis moves our attention deeper into a sequence of numbers.
Obtaining the distribution of numbers is a critical process. However, there are degrees of uncertainties that actually play in favor of eventual positive utility. No matter how the distribution occurs, visual acuity can reinforce interpretations of the meaning of cluster patterns that are made by the human.
At the beginning of our current project (November, 2000), we do not know how we will handle the CCG visualization task.
Our thinking is that identification of tokens should be followed by the identification of a relational linkage between tokens. However, how does one impose such a relational linkage given the nature of human concepts?
Reinforcement learning
within an image space?
A mapping could be developed between CCG images, derived in some way, and objective physiological, psychological, and other medical parameters. The mapping might be complex, in the sense envisioned by the tri-level voting procedure, Russian Quasi Axiomatic Theory, or it could rely in a simply fashion on visual acuity. The CCG – technique separates and then organizes regular patterns using a two-dimensional grid and color-coding. We are looking for a separation and organization process that makes sense of non-regular patterns.
It might be that normal distance metrics on CCG – type images might produce an ability to automatically parse new text for concepts – simply using a distance in image space.
Our study may not find anything. However, finding something may result in a quantum step in what is now an effort that has very little positive results. This effort is the automation of conceptual parsing of data streams.
Other Domains
An interpretation of the data invariance in data from astronomical sources might be also be made. In this case a relationship would be found between various types of invariance in the data, as identified by a CCG type image, and scientific interpretation of that invariance. A reference system could be developed that extrapolated between visualization.
This domain appears greatly simpler than the domain of text parsing. However the Russian application of CCG visualization to scientific data streams is expected. This expectation is based on spare conversation with several Russian scientists, including Alex Zenkin.
EEG data has been considered, however, the problem has been the acquisition of data as well as the development of a methodology for elucidating knowledge from knowledgeable persons in the field of EEG analysis.
Aside from EEG analysis, there are other domains of scientific data that are being looked at in Russia. We look forward to seeing these results.
Content Evaluation
We have chosen to investigate the domain of content evaluation. The problem seems to be the most difficult and have the most potential for a true breakthrough. However, we are well aware of the considerations that come from any proper understanding of the deep issues.
Content evaluation for full text data bases might follow a specific approach:
1) a inventory of CCG type images is recognized by a human as having value
2) the images are used as retrieval profiles against CCG representations of text not yet recognized
3) an associative neural network would take reinforcement into account in the modification of semantic interpretation
Several theorists have identified a problem. This problem is stated well by Alex Zenkin when he talks about expert knowledge and the role of well-defined goals to the CCG based vetting process.
Comments from Alex
Zenkin:
VISAD works with any set of objects that is described by any set of tokens (signs, properties, etc.).
The set of tokens must include semantics on the set of objects.
The required semantics is defined by common goals of the problem under consideration (purchase, sale, advertisement, production, market, etc.). It is obvious, that objects will have different sets of tokens depending on the goal.
The requirement for goal-oriented information means that it is impossible to describe all objects of a large patent base by an unified set of tokens.
Not knowing terminal aims and semantic features of objects, I can construct a set of only formal syntactical, grammatical, and statistical tokens.
However, I see the following possibilities.
First of all, we may formulate the terminal goals
1) Why we need to analyze the data?
2) What kind of problems will the new knowledge help us solve?
We may extract from the patent base a class of related objects (say, by means of key words).
A set of tokens related to terminal goals must be constructed by professionals in the problem domain defined by the terminal goals.
VISAD usage:
We may use VISAD in order to:
1) Visualize the given class of objects.
a. The class will have a distinctive CCG – type image that is used as an icon
b. The icon will have possible dynamics. Zenkin has suggested that Lefebvre type gestured images be used as a control language
c. Prueitt has developed some notion on state / gestures response interfaces to contextualized text databases.
2) Define more accurately the initial set of tokens
a. It is an interactive process of experts with the problem and of learning their professional knowledge and intuition.
b. Our experience shows that professionals frequently find out new ideas and solutions during VISAD usage. (AZ – do we have an example of this?)
c. Vladimir Lefebvre's has useful ideas on reflexive dynamic interaction "expert – an experts group", "expert – visualized problem"
d. Vladimir Lefebvre's "faces representation" for qualitative analysis of situations might be useful here.
3) Automate (with a visual CCG-support) classification of the given class of objects
4) Automate (with a visual CCG-support) creation of notions on classes
5) Creating a mathematical (logical) model of the kind "What will be IF …" or "reason - consequence", "cause - effect", etc
6) Automated (with a visual CCG-support) recognition (purposeful search) of objects in image-structured information base.
Additional comments on
VISAD by Alex Zenkin
VISAD usage allowed us to make clear well-known information on logical and mathematical paradoxes (about 20 objects described by about 20 tokens). We discovered some new tokens, made a new classification of some paradoxes, and formulated notions on necessary and sufficient conditions of paradoxicality as a whole. These notions disclose the nature of paradoxicality.
Main stages of this work
are described in my paper "New
Approach to Paradoxes Problem Analysis" published in "Voprosy
Filosofii" (Problems of Philosophy), 2000, no. 10, pp. 81-93 (see
Annotation, today so far in Russian, at
http://www.com2com.ru/alexzen/papers/VP2.doc.
The VISAD and its usage to analyze large bases of text unstructured DATA is a large independent project.
When I asked for large DATA files I had in my mind our joint project as to CCG-analysis of large time series, f(t), of the EEG-DATA type. If you have such f(t)-files, send them to me. It would help us to make a good presentation in the project.
Note from Paul Prueitt
to Alex Zenkin November 17, 2000
CCG analysis of EEG data is a complex task. The data set that I received from Pribram’s lab has what is an unknown format of the numbers. Figuring out this format has stopped my attempt to put this data together. I will try once again to get some support from the lab.
However, once this data format problem is figured out, we still have the difficult issue of how to make sense of the syntactic structure that might be imposed
For this reason, I have turned to the unstructured text domain, since I know that I personally can solve the conversion of text to numbers and categories problem.
My hope was that you would be able to find both a source of data and the expertise to make a small experiment in Russia. I still hope that you will be able to solve both these pragmatic problems and thus produce an prototype application of CCG to unstructured scientific data.
Criterion for knowledge creation
We have developed a metaphoric linkage between Zenkin’s CCG application to number theory and parsing and interpretation applications to other data sets. The linkage is related to the notion of induction, Zeno’s paradox, Cantor’s diagonalization conjecture, and Godel’s complimentarity / consistency arguments.
In our view, knowledge creation occurs when a jump occurs from one level of organization to another level of organization. This jump is referred to as an “induction”. The scholarship on this notion of induction is concentrated in the area called ecological physics (J. J. Gibson, Robert Shaw) and perceptual measurement (Peter Kugler).
In the case of mathematical finite induction, the jump occurs when one assumes an actual infinity, and uses this assumption in the characterization of the positive integers. In the case of Zenkin’s principle of super induction, the jump allows the truth of the presence of one condition to be transferred to the proof of a theorem.
Zenkin’s principle of super induction is still an induction that occurs about formal structures that are regular and linear, even through perhaps intricate.
One requirement for CCG application to number theory is the existence of an infinite sequence of positive integers – generated by the Peano axiom and the imposed property of addition and multiplication. This sequence serves as an index on sequences of theorems. The objective of both induction and super induction is to find a way to demonstrate that the truth of an intricate relationship transfers. The transfer is between secession (Peano axiom), addition and multiplication properties of integers. This transfer will exist beginning at some point and then continue being true from that point in the sequence of theorems.
With any representation of concepts in text, we have a different situation. There is no relevant truth-value that can be assigned to some relationship between numbers, or so it seems at first glance.
Use case type analysis
of the process (A.1)
A.1: Convert the word sequence into a sequence of stemmed words.
A.1.1: Take the words in each document and filter out words such as “the” and “a”.
A.1.2: Make replacements of words into a stemmed class:
running à run
storage à store
etc.
A.1.3: The set of stemmed classes will be referred to as C.
Use case type analysis
of the process (A.2)
A.2: Translate the stems to positive integers randomly distributed on a line segment between 0 and 1,000,000,000.
A.2.1: This produces a one-dimensional semantically pure representation of the word stem classes.
A.2.2: The topology of the line segment is to be disregarded.
A.2.3: A new topology is to be generated by adaptively specifying the distance d(x,y) for all x, y in C.
Use case type analysis
of the process (A.3)
A.3: Introduce a pair wise semantics
A.3.1: Following a training algorithm, points are moved closer together or further apart based on either algorithmic computation or human inspection
A.3.2: Topologies can be produced by various methods.
A.3.2.1: Generalized Kohonen feature extraction, evolutional computing techniques.
A.3.2.2: From one point topological compactification of the line segment, and cluster using the Prueitt feature extraction algorithm.
Use case type analysis
of the process (A.4)
A.4: Pair wise semantics can drive a clustering process to produce a new semantically endowed topology on the circle.
A.4.1: Features of the new space are identified by the nearness of representational points
A.4.2: Prueitt feature extraction is seen to be equivenant to Kohonen feature extraction
A.4.3: Prueitt feature extraction produces a specific distribution of points on the unit circle.
A.4.3.1: The Prueitt distribution is defined as a limiting distribution which has semantically relevant clusters
A.4.3.2: As in associative neural networks, and other feature extraction algorithms, the Prueitt distribution is driven by a randomization of selection (of the order of pairing evaluation), and thus is not unique to that data set.
A.4.3.3: Iterated feature extraction produces a quasi- complete enumeration of features, encoded within a topology.
A.4.3.4: The limiting distribution has a endowed semantics.
Use case type analysis
of the process (A.5)
A.5: The clustering process can be mediated by human perceptual acuity
A.5.1: Phrase to Phrase association by human introspection as coded in a relational matrix.
A.5.2: Latent Semantic Indexing for co-occurrence, correlation and associative matrices.
Use case type analysis
of the process (A.6)
A.6: The limiting distribution is viewed via CCG methodology
A.6.1: The CCG methodology is linear and assumes a regular limiting distribution.
A.6.1.1: The CCG technique finds a coloring patterning and modules (related in the number of columns in the grid), such that a principle of Super distribution can be used to prove a specific theorem using the limiting distribution.
A.6.1.2: Coloring pattern and modules is specific to the theorem in question
A.6.1.3: Given a limiting distribution that is metastable (a pattern is repeated) or stable (one condition is show to exist always beyond a certain point), then a theorem exists.
A.6.2: A non-linear CCG technique might have a grid of dimension higher than 2, as well as transformation operators that are statistical.