Tuesday, December 07, 2004
Center of Excellence Proposal
à
White Paper on Incident Information Orb
Architecture (IIOA) à
Types of Ontology for Crisis
Management à
Adi Structural Ontology Part I
à
Cubicon language description
à
Paul Prueitt
Foreword: It is a concern to any scholar that histories be complete and fully
referenced. The problem with the recent
history of Information Science is that so much of the standard cultural rules
of business and of government agencies have made non-communication an essential
part of the economic survival of anyone who is in the information technology
sector. There are many reasons for this
cultural condition, and we have addressed some of these in the bead games. For now, and for this 2004 revision of
three short 2001 papers, we will treat our presentation as if a history. This history is incomplete, and for this we
apologize in advance.
Market Delineation for Structural Holonomy
Process Model for In-memory Databases
Market Delineation for Structural
Holonomy
First Draft: May 21, 2001 (published at
Ontologystream.com)
Paul Stephen Prueitt
In this technical paper, we
provide the definition of a class of innovations called structural holonomy.
The
essential feature of structural holonomy is that it is a compact representation of
the structure of information. The
practical aspect of this feature is that types of information aggregation and data ware housing
can be done in real time in small memory footprints.
Introduction
OntologyStream technologists have partitioned the market for structural holonomy into six market spaces. This partitioning could be delineated in a different fashion than as is shown in Figure 1. This partition serves to descriptively enumerate market needs so that a value matrix can be revealed.
The value matrix has markets as matrix rows and two types of matrix columns.
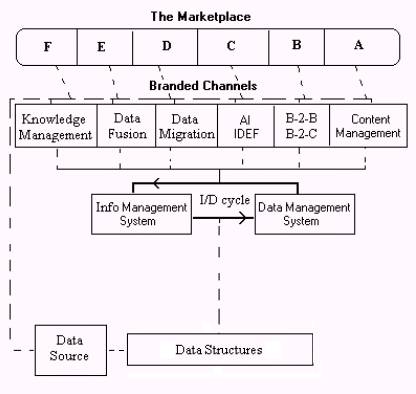
Figure 1: The market place
National Defense Technology does not appear in Figure 1. A separate market delineation and related value matrix was used to encode the needs and capabilities of structural holonomy in the context of National Defense Technology. The development of this matrix can be extended and then related to specific types of technologies and products.
Section 1: Knowledge Management (KM)
KM has become the branded term for sharing knowledge within communities. In 2001, Autonomy Inc. is perhaps the branded lock-in with a web-crawler type “Dynamic Reasoning Engine” (DRE). The Autonomy DRE builds collections of profiles (smart agents) that push and pull information about people, places and things into Internet (Intranet) locations. Semio and Tacit Knowledge Systems have variations on the Autonomy lock-in. Lotus Notes Raven system has some additional innovations, particularly in the direction of distance learning. By 2004 very little advancement has developed beyond these systems as they were in 2001. The pause in innovation has established the potential for a sudden ignition of Semantic Web and Anticipatory Web systems.
Between 2001 and 2004, OntologyStream scientists have developed a plan that involves replacing the relational database technologies that underlie several of the knowledge management technologies. For example, Ncorp’s mission statement:
"Ijen from NCorp
offers a revolutionary new technology which enables users to intuitively and
intelligently interact with structured information. …. NCorp's powerful new
technology provides a mathematical understanding of database content which
allows it to immediately and dynamically provide the most accurate, relevant
information to end-users".
from www.ncorp.com.
In 2001, the application architecture for Ncorp’s ljen technology had a
relational database at it’s core, with a translation layer, or wrapper, that
uses Autonomy technology (composed mostly of algorithms) to act as an
intermediator between e-commerce applications and the data. We felt that the OntologyStream plan could
be modified to develop a competing technology to Autonomy. A series of proposals
were made to government agencies and these proposals helped us develop the Orb technology. During this time, the KM space receded in
interest to us, and we began to focus on the anticipatory web technology.
In 2001 we felt that solutions, such as provided by Ncorp, might
transform structured information systems, such as e-commerce sites, in an
extremely efficient and elegant manner.
However, the relational database was seen as the weak link in this chain. We felt that structural
holonomy was a clear
alternative that can be made to sit within the Ncorp architecture. The step in between has become clear. This step is XML encoding of data with the related XML web services. With XML encoded data, the data looses a
single structure and can quickly assume organizations that might not have been
anticipated during the design of a relational data model. (see the book [1] )
In-memory databases such as TimesTen’s core “in-memory database
technology” have been oriented to SQL optimization and relational databases
with normal forms. This in-memory
technology is not of the same category as the structural holonomy technology. We will try in 2004, to explain why we say that in-memory
databases, like TimesTen and Ncorp, are not in the same category as structural
holonomy.
In 2004 we have come to believe that structural holonomy will eliminate the existing generation of
relational databases and SQL completely, while being interoperable with legacy
data systems. The special relationship
to XML is being studied. Here also,
however, we have come to believe that CoreTalk and other optimal standards will
come to replace some parts of the XML component architecture.
The XML component architecture involves the following elements:
XML namespaces
DTD Document Type Definition
XML Schema
DOM Document Object Model
Xpath
Xlink XML linking
XSL and XSLT
RDF Resource Description Framework
SOAP Simple Object Access Protocol
WSDL Web Services Description Language
UDDI Universal Description Discovery and
Integration
ADML Architecture Description Markup
Language
We believe that these architectural components are the next step in the
evolution of Semantic Web phenomenon and the use of web services. (see the book
: XML in data management, by Aiken and Allen (2004))
An essential feature of structural holonomy comes from the class of transformations that can be applied to data encoding standards. These transformations include the formative projection where interaction with a human is assumed and leads to a validation of the projection. The projection is a query that returns a view of the structural holonomy by selecting a subset of the n-aries in the Orb set. The subset is then used to create the graph form of the Orb set, and the user can view the Orb either as a complete object or focus on topological neighborhoods.
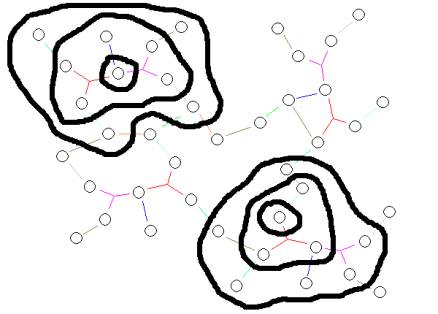
Nearness in Orb graphs produces topological neighborhoods
Meaning can be perceived when a human looks at the names of elements, topics, which are close to each other in the Orb. In this sense the Orbs are semantic webs.
The view of a subset of an Orb set must be considered non-validated due to the differences between human perception and algorithmic processes. The development of the notion of nearness can come form a number of algorithms, such as latent semantic indexing or other co-occurrence algorithms. As community consensus develops around specific Orb constructions, we may create artifacts that can be streamed to different parts of the community in a just in time and on need basis.
A class of architectures for knowledge portals can be found at www.kmci.org. The architectural specification for knowledge claims and knowledge validation can be reviewed by visiting this web site.
Section 2: Data fusion is an entrenched problem with large research and development projects. However, the way in which a data system based on structural holonomy addresses this problem is revolutionary. The fusion becomes a matter of loading data into a single structure and performing arithmetic like operations. In the case of the Orbs, this is called Orb arithmetic. Orb encoding into computers has two forms. The first is a simple text file with the n-aries, or order triples in some cases.
< relationship, bob,
work, downtown>
< relationship, downtown, target, attack>
Heterogeneous data can loaded in a structural holonomy data structure. Once in this structure, data from two different sources can be made to appear as from one source; e.g., arithmetic operations can be performed. Scatter- gather and existing relational information (from the tables’ key structure) can produce very fast In-Memory processes. This distills information from data invariance. Data aggregation in this numeric space will cluster tokens in such a way that individual tokens can be moved from one of these structural holonomies to another. As of late 2004, we have not developed the type of easy to manipulate control software for evolving Orb constructions into knowledge artifacts. This has been only due to our merger resources over the period 2001 through 2004. Our core group has often talked about how this might be done.
A neuropsychological grounding to structural holonomy architecture used with the OntologyStream Tri-Level architecture is provided in Prueitt’s published work. The published work references Karl Pribram’s holographic theory of brain function, as well as work in ecological complexity (Robert Shaw, J. J. Gibson). This scientific literature reveals the structural holonomy as an expression of natural phase coherence in electro-magnetic domain, as mediated by the neural connections. In this domain, data fusion has a solution that can be interpreted as reinforcement and collision of wave fronts. More is said on this subject in the published research of our colleagues at the Einstein Institute.
Market spaces for data fusion include B-2-B and B-2-C both in government and in commercial spaces. Data fusion also is involved in some of our preliminary notions about how structural holonomy can be employed in image compression and image understanding, as well as in real time simulation of complex environments such as computer games and battlefield simulation.
Section 3: Data Migration
Data migration is a very difficult proposition in today’s market spaces. Data base technology has evolved over the last few decades, and each stage of this evolution has involved the introduction of new barriers to interoperability between database vendors and even the different versions that one vendor has sold into the market space.
This is a problem that almost everyone has.
Several technology groups are developing structural holonomy technology for the data migration / data integration / data renewal problem. The two most deserving of mention are CoreTalk Inc and Knowledge Foundations Inc.
The data migration problem has developed to have very specific characteristics. One of these being that most professional don’t believe that the problem can be overcome. However, revolutions often occur exactly when there are many who feel that the situation cannot change.
Section 4: Agile Interoperable (AI) IDEF
Agile Interoperable IDEF is a standardized methodology used in the government to engineer business processes such as e-procurement and government payroll.
One can envision a product that is developed in three phases:
1) An application that creates, modifies and maintains IDEF0 drawings and IDEF1 diagrams
2) An application that opens a hyperlink-style information portal for each Active Object in the IDEF0 drawing
3) An application that provides Agile, interoperability to heterogeneous data sources related by, but not normally accessible from, the IDEF0 drawing.
IDEF is directed at modeling processes using a standard framework. This framework is well understood and is presented elsewhere.
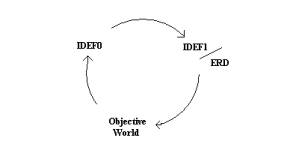
Figure 2: The standard life cycle for IDEF
The standard life cycle for IDEF (see Figure 2) produces a IDEF0 drawing depicting processes in a nested structured fashion. IDEF1 is a relational diagram that corresponds to a Entity Relationship Diagram (ERD) used sometimes to instantiate information into a relational database in Codd third normal form. The Objective World is derived from communities’ consensual agreement as description of the set of processes underlying the work effort.
One limitation of the IDEF life cycle is that the IDEF0 is not always fully modeled by the ERD due to incomplete or inconsistent information.
A second limitation is that the world of natural processes is non-stationary and introduces novelty in such a way that exposes the ERD to fundamental design changes.
A third limitation is that there
is often not enough time to develop the optimal IDEF0 drawing. A fourth limitation to the IDEF life cycle is
that the community may have an intervening agreement about what the work
process is that is not functional or that is based more on political issues as
opposed to other types of functional issues.
Let us consider an abstract problem. Suppose that the X system is governed by the IDEF life cycle. Suppose also that the current X IDEF model shows business rules down to a program level and that there are 8273 such programs with average length of 725 lines. Each program, in theory, implements code that conforms to some part of the set of business rules.
In truth, the logic of business processes will deviate from the code. In the typical case, the X code took 30 years to evolve. During this period, there where often times in which design shortcuts where required by the contingencies of policy directed changes to the business rules. Part of the impacting contingency is the difficulty of updating an increasing complex relationship between older code and new code. In many of the large government data systems, the divergence between code and business logic now often represents an intractable problem given known tools.
Suppose now that a 600-member team of specialists has been tasked to maintain the X System by developing a model. For the sake of this discussion, we will refer to this model as the “X Code Model”. The body of the X Code Model is used to attempt to prove that inputs and outputs comply with a specific IDEF drawing, and that auxiliary information and data resources are well formed and correct.
The challenge is not only in proving that the current X Code Model is well formed and correct. Continual change is introduced from Policy and Guidance authorities. In addition to reducing divergence between the code and the business logic, attempts are made to conform this business logic to what is intended by policy and guidance.
The X Code Model is produced by
1) reverse engineering application and
2) through discussions involving software engineers and specialists within the 600 member X team.
Figure 3 represents a view of the migration and update of IDEF drawings. The historical process (a, b, c) implemented code based in a three step process that starts with policy and guidance. To the degree necessary to keep the current X system operational, this historical process remains in place.
Process d was completed as an intermediate step whose final objective is to produce an IDEF0 drawing having active objects pointing to process logic, the programs that compute this process logic, and to other informational recourses. This intermediate step was accomplished primarily using a reverse engineering workbench. Some documentation of the code has been made that assist in the one to one correspondence between elements of the business logic seen in the IDEF drawing. A separate software tool accomplishes the production of IDEF drawings.
The relationship between the IDEF drawings and the collection of COBOL programs is managed by hand.
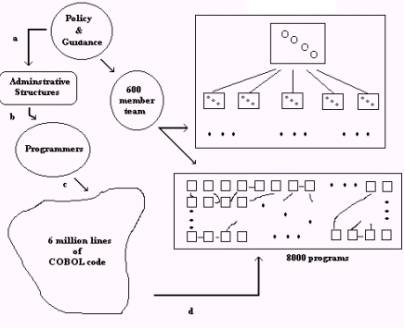
Figure 3: Current model of Process
Figure 3 represents a model of the current migration and update of IDEF drawings. Aside from unavoidable limitation of the standard IDEF practice, the model suffers from the complexity of the legacy system and the uncertainty of continuing alterations in business logic.
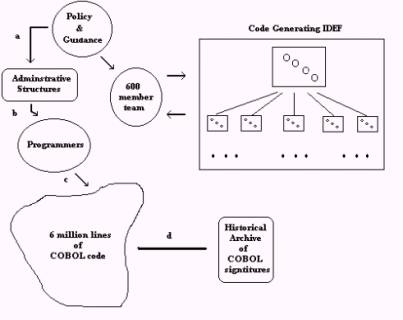
Figure 4: Desired next state model
Figure 4 depicts an idealized process whereby snapshots of the entire 6 million lines of COBOL code is encoded into a structural holonomy each day during a period of transition.
The archive deploys structural holonomy technology to compress the original data source (lines of COBOL code) into a data-warehouse.
To move a legacy system to this state we need the following milestones.
1) A transition process that has resulted in a provably complaint Code Generating IDEF Drawing Workbench.
2) A Code Generating IDEF Drawing Workbench that has demonstrated the prototyped ability to generate and maintain business logic and implementing code within a one-to-one correspondence.
3) A Code Generating IDEF Drawing Workbench that has demonstrated the ability to generate and maintain all business logic and implementing code in a one-to-one correspondence. (Equivalent to: prototype properly scaled and placed in an operational environment.)
4) During the transition a historical archive would be created to give confidence that migration processes are reversible under the condition that the replacement system has a failure.
Given these milestones, one is ready to support the migration of centralized responsibility to the organization Q.
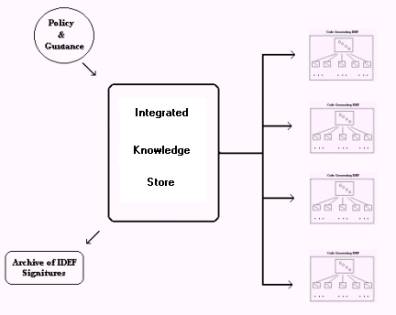
Figure 5: Final
state of the system
The final state of the transition process leads to Q’s control of implementation at distributed and situationally distinct systems. Q’s responsibility is to implement policy and guidance and to preserve daily records of the entire state of many code generated IDEF0 drawing.
Section 5: B-2-B and B-2-C is the most visible of all application areas for new computer and Internet technologies. OntologyStream developed a general architecture for B-2-B that involves Topic Maps as a control interface and structural holonomy technology as a virtual information machine. Knowledge Foundations Inc and CoreTalk have even better developed architectures.
We are claiming that the relational database is being replaced by new technology having structural holonomy at its core. It has been mentioned that the entire market can be partitioned into six market spaces. This partitioning overlaps. Perhaps the best example of this is the fact that B-2-B and B-2-C is an application of Content Management. Content Management is a more general technical problem. CoreTalk, Knowledge Foundations and OntologyStream are pursuing strategies that leads to a product line for KM. OntologyStream’s plan integrates Topic Maps, the OntologyStream’s Tri-Level Architecture, and the structural holonomy database.
Section 6: Content Management has three aspects (1) content evaluation (2) Peer-2-Peer content-streaming and (3) content publishing. The structural holonomy technology provides solutions to the content evaluation space. Topic Maps provide the solution set to the content publishing space.
Content evaluation has a great deal in common with B-2-B and B-2-C and KM since content evaluation has a context determined by an individual or organizational viewpoint.
Process Model for In-memory Databases
Section 1: The Database Update Problem
In-memory databases have certain nice properties. However, in-memory mapping process relies on memory-mapped location as an actual property of the information.
The problem of adjusting data positions in memory has been with the standard relational database since it’s beginning in the 1950s. The “best solution” to this problem was to
1) define normal forms for the relational database,
2) define a file system for breaking the data into tables, and
3) create a data manipulation language for record updates.
This “best solution” is not good enough. Data mapped in-memory cannot easily be broken up into smaller units and moved around. In fact, in-memory database systems use the mapped data as a single mathematical object. The object cannot be altered in any way, or else the system breaks.
Imagine moving numbers around arbitrarily so that the number “5” is sometimes in front of the number “4” and sometimes after the number “4”. The meaning of the tokens “4” and “5’ are arbitrary. But once established, the arithmetic has a specific meaning as in “5 is the integer that follows 4”. This ordering cannot be destroyed without affecting the arithmetic.
Data needs to be updated. The update is required to reflect changes in the information available at a specific point in time. In fact, the structure of data also needs to be updated periodically to reflect a deeper alteration in the nature of complex systems such as business-to-business relationships and even the conduct of military or political matters.
However, the absence of a delete function is NOT a flaw for a strictly non-transaction technology. If the database is non-transaction then the view of the data can be very fast. Standard analytic processes (of any kind) can be run at great speed. These processes include scatter-gather methods (such as Latent Semantic Indexing), neural network cluster algorithms, evolutionary programming methodologies, emergent computing methodology, and any of the new data mining algorithms.
Scatter-gather methods produce a structural model. Derived (or mined) information can be placed in the structured model. For this mining process to work well, a process model is needed. The process model provides a basis for data updates within a specific structural model. The process model also must allow updates to the structural model itself. The trivial solution to the in-memory databases transactional problem will be one that minimizes the cost of the process model measured in processing cycles and allocated memory space.
Section 2: A Process Model and New Categorical
Specification
Data object transformation requires a process model and a categorical specification of the abstract type for objects. The standard relational architecture is one way to specify a process model and abstract type. Taken together, Extensible Markup Language (XML) and in-memory databases suggest a different specification.
There exists a framework to solve in-memory database transactional problems. In general and abstract terms, this solution creates a transactional database with an analytic engine as an "object" (the object here is a category of simple mathematical constructs). A data manipulation language manages the object. A separate formative process manages the specification for the category of objects.
The architecture is a standard three-tier model {presentation, logic, data} for database applications. This architecture is a natural consequence of the update problem. The presentation layer allows users and developers to define behavioral features for the software. The logic layer allows developers to place transactional engines that perform essential tasks that support the required behavioral features. The data layer is where data is placed for use by the logic layer.
Our framework leads to a process model where by the analytic database is dissolved and reconstituted on a "commit" command. All data updates are handled in a temporary way, until the "commit" and then a new object is created. This new object is again purely analytic in nature, and may be treated as such. The commit command simply allows one to control WHEN this "costly" update computation will occur.
Our process model provides for data updates within a structural model and periodic updates to the structural model. Such a solution is ideal for products that require a fast interaction between human perception and data structures.
A relationship exists between a data structure and some object in the world. In the Topic Maps conceptual model, this relationship is indicated by delineating subjects into machine addressable subjects (such as text in an ASCII file) and subjects that are not addressable by the computer. The addressable relationships, and only these addressable relationships, may be used to produce the single mathematical object.
Data updates require a transactional database equipped with a data manipulation language. However, periodic updates to structural models require something new. What is required is a formative process, involving the human perceptual acuity. The consequence of this update can be instantiated as a single mathematical object. This object, once instantiated can be placed in-memory and serve analytic purposes.
Section 3: In-memory databases can be Equipped with a Process Model
In January and February of 2001, Prueitt developed a notational system for ”Semantic Situation Algebra" and provided a description of how to index a large collection of Intellectual Property text.
The notation system involves the use of what logicians call a syntagmatic unit having the form < a, r, b> where a and b are data invariance and r is a relational operator. In theory, any in-memory database can be completely described using this notational system. Prueitt has published work on this notational system since 1995. In late 2000, he created a small test collection using fables to simplify an anticipated development process for a technology client.
An in-memory database can be used as a static construct category on which to run a class of transforms (defined over the construct category). In April 2001, he began to use the term structural holonomy to indicate the general construct. Conceptual work has been completed on how the construct might serve as an analytic engine and transactional database.
It is clear that any reduction-to-practice of generalized structural holonomy will take a few years. A technical review of the prior art has produced a rich linkage to fundamental problems in scholarly literatures, to existing patents and to patent applications. An ability to show prior art is an issue to consider.
Structural holonomy can be created using any of several basic mathematical formalisms, such as a Fourier Transform or wavelet. The concept is simple and straightforward. In my mind, anyway, the notion is grounded in the neuropsychological literature of Karl Pribram and the ecological literature of Robert Shaw and J. J. Gibson. Pribram’s 1991 book is called “Brain and Perception: Holonomy and Structure in Figural Processing”.
The Topic Map conceptual model has features similar to those features discussed above. Topics within scope must remain within a whole construct. The "add topic" function requires the entire Topic Map construct to be re-instantiated. The Topic Map is a structural holonomy, but is not generally considered an in-memory data structure.
A similar problem, and a similar solution, is present with the in-memory database systems being developed by NCorp. NCorp uses a structural holonomy, as does Excalibur and several others. Discussions continue with companies in this regard.
Full Text Mining
Document Organization into
an Information Warehouse
The book, "Oracle Data
Warehousing" by Donald Burleson, and other recent books on data warehouses,
indicates two modes of data warehousing operation. The first is a mining mode
supporting autonomous data warehouse analysis. This mode is supported during
system design cycles and in lights out operations. The second is a discovery
mode.
Discovery processes use the
data developed during the mining operation, and are run separate from the
mining mode. The idea is that discovery requires a pre-processing of massive
amounts of data and the interaction of the user. Once the organization
of the data warehouse reflects statistical properties of data use patterns, the
discovery mode can be used interactively to produce an information warehouse.
The commercial literature,
such as Burleson's book and the book from the SPIRAL Group "Data
Warehousing and Decision Support", suggests that a mature data warehouse
should not be updated while users are accessing the system. In this view,
updating and analysis occurs either over the weekend or at night. The
separation is between computationally intensive data mining process and user
discovery using aggregated data.
Other literatures, for
example research at IBM, suggest that a formal separation of lights out
operation from user access may be viewed differently if data is compartmentalized,
via data replication. In general, the community is attempting to clearly
understand analytic transformation of transaction data and the process of
clarification has put some pressure on traditional views of data base
administration, information, and artificial intelligence.
OSI’s General Framework for
Machine and Natural Intelligence suggests that the modal nature of perception,
memory formation, cognition, and action should influence the architecture for
information mining (data mining plus text mining) and knowledge discovery in
databases [1,2,3,4,5]. Regardless of the hardware and software constraints,
there is direct evidence, from the neuropsychology of memory and cognition,
that a pre-processing mode should occur and that during this mode learning
modifies implicit memory stores at the substructural level.
Practical aspect: The grounding of OSI’s
General Framework in modern experimental literature on human perception is good
business, because the Framework is endowed with long-term value.
We suggest that data mining
can produce specific tacit knowledge about the object invariants in the data as
seen through the analytic processes. This leads to the notion of Computational
Implicit Memory or CIMs, and retrieval processes based on the voting procedures
discussed in [3, 6]. OSI calls this retrieval process “Implicit Query” or
IQ. CIMs was a concept developed by
Prueitt in 1998, and has now been replaced somewhat by the notion of structural holonomy.
Autonomous reorganization of
memory (be this human or corporate) requires a global lights out process. For
example, the categorization policy (a partitioning function that is applied to
the entire data warehouse) has to be globally reevaluated due to the
non-stationarity of experience. This evaluation need not be continuous, so that
periodic update is acceptable. For data mining systems, a global partition
function can be the cause of "object consistencies" that are them
modeled by aggregation techniques, and represent a memory of the past as
reflected in the data invariances. Laying out this framework for memory of the
past is the first requirement in the transformation of a "data
warehouse" to an "information warehouse".
However, a real time
adaptive modification of within category linkage is a second feature of
biological intelligence. Real time user induced changes to the structure of
memory is a capability that can only be considered given an adaptive architecture
for partitioning the substructural features into the "object
consistencies". User induction can be supported at both the level of
object components (theme expression, cognitive graphs, etc.) and at the level
of some meaningful aggregation of components. Thus, the
"interpretation" of an aggregation of data can be guided by the
discovered interactivity of subcomponents. Subcomponents analysis forms the
basis for OSI’s notion of knowledge warehousing.
The OSI Information Mining
architecture is primarily motivated by the ability of computer systems to do
various types of tasks. The user is required to do another set of tasks.
Knowledge acquisition picks up the results of information mining and through
interaction with a user, develops "knowledge" through the validation
of the degrees for which meaning can be assigned to substructural aggregation.
The distinction between
information and knowledge is subtle, and relates most closely to the issue of
which information can be "validated" as meaningful (to an organization
or some other real entity.) The Computational Implicit Memory (CIMs) is a
representation of statistically valid patterns in the data.
The CIMs can be regarded as
stored knowledge, only when the database that store CIMs have a means to
validate the meaningful interpretation by a human user..
The separation of data
access from data organization provides a stable warehouse for users to interact
with, while the lights out analytic mode provides an opportunity for experts
and database administrator to examine user queries, data base performance, and
data aggregation. In the books by Burleson and the SPIRAL Group, the modes are
regarded as a "mining" mode and "discovery" mode. The
mining mode places raw material into a configuration.
Discovery can be achieved by
the act of a human operator or some other automated process depending on a
successful mining operation.
Review of the technology
The four classes of mining
functions are:
1.
associations,
2. sequential patterns,
3. classifiers and
4. clustering.
Associations between two
patterns (or data units) can be as simple as the observed probability that if
one occurs then the other occurs. Co occurrence provides one means to develop
an enumeration of relationships that are observed to exist between patterns.
The set of all these patterns, and the potential relationships derived from
empirical evidence, is information (or aggregated data).
The process of discovering
the consequences of co-occurrence is less well supported in existing
commercial software, and leads from information technology into knowledge
technology. The Founders of OSC have investigated a version of Mill’s logic that discovers and manages
information about the consequences of word or token co-occurrence. This
preliminary work suggests that the voting procedure, used with Mill's logic,
can make an assignment of relationship based on a theory of types and
stratified category representation.
Full text representation is
the first step in information mining and knowledge acquisition.
Tool sets exist for
representational substructure and sign systems, discovery tools based on neural
network models, and data warehouses.
Layered neural networks can
assign a pattern to a category and in this way associate a pattern to use
behavior. Thus, neural network architecture is appropriate for the encoding of
knowledge representations. Data warehousing language reserves the terms
"category" and "cluster" for the output of an artificial
neural network. Neuro-technology encodes associations between levels of
organization (pattern to cluster) or between patterns in a reinforcing context.
One expects that there is at
least some unadvertised use of neural networks as part of data mining and
knowledge discovery - particularly in financial analysis of real time data.
Data mining’s discovery mode
identifies some refinement of simple co-occurrence associations. Aggregate objects are formed to filter and
rout data during the next mining cycle.
There are a number of
potential knowledge technologies. For example, one could extend the probability
of co-occurrence to fuzzy associations by assigning language terms such as
"strong" "moderate" and "weak" to a description
of the association.
Sequential patterns are
associations across time. Associations between complex objects, such as
clustered units, are also possible. In the Oracle and IBM literature, it is
generally assumed that users make discoveries. Most of the commercial
literature is focused on how the data is managed and not on how the data is
used or what are the foundations of a theory of knowledge discovery.
Oracle and IBM technology
and tools organize data to detect patterns, and then develop aggregates
(perhaps fully defined as objects) based on semi-automated analysis. The data
patterns are then assigned metadata to speed access to the aggregated data
structures. The aggregates can be supported by frame filling tools that add
information and develop quick access to pre-processed information. Frame
filling enrich the definition of patterns.
Clearly there are some
strategy decisions that are made, regarding the role of users in discovery. IBM
places responsibility on the data warehouse system to lay out data in a way
that users can discover value.
A clear separation can be
made between mining functions that autonomously identify sequential patterns,
and aggregations functions that nominate units as being of high importance.
The "higher order
processes"; such as pattern completion (a form of categorization)
forecasting (even in it's simplest form), selective attention, hypothesis
testing (again in it's simplest form), and goal formation, are part of the discovery
mode.
Discovery implies that there
can be very little automation of these processes until the nature of
information mining and knowledge discovery is better understood. We must rely
fully on the human to make this type of judgment until advanced machine
intelligence provides to us a new means to discover the meaning in aggregations
of patterns.
Document Representation
based on Features Extracted and Relational Associations
As we know, traditional
Information Extraction and Retrieval (IR) methods require a set of features
through which retrieval is supported. The retrieval can be enhanced by Salton
query expansion and other advanced query aids. Information Warehousing and
Knowledge Extraction moves us beyond IR by requiring that aggregations of features
be formalized as objects. Sometimes the cost is a selective violation of Codd’s
third normal form. This occurs in order to provide better access or
visualization of these aggregations of features.
The voting procedure identifies and refines
aggregations of features and is thus an ideal data warehouse management tool.
The procedure is neutral regarding how features are identified and extracted,
and whether query expansion operators are available. Also the procedure will
integrate with any of a class of existing feature extraction tools including Topic Maps.
The results of third party
classifiers or cluster production systems can be used to define category
policy. For example, a neural network classifier could be used to sort messages
into categories. The sorted messages could then be used to define a category
policy. Iterated ranking and trimming of the representational sets refine the
policy. Refined category policies may be used to generate a description of the
contents of the categories and these descriptions used to initiate
informational seeking programs. The description of the categories can be
associated to other descriptions in a hierarchical fashion.
Data warehouse standard
relational association tools are based on the co-occurrence of tokens and the
"affinities" that tokens have for each other. The tools are generally
based on statistical methods such as statistical regression, but can also be
based on adaptive systems such as neural networks. However, the results are
handled through some "presentation" software that shows these
affinities to the user. If the user is provided with proper tools and has
proper background knowledge, then affinities can be further refined.
The affinities are generally
stored as a matrix, where the array elements is a measure of co-occurrence,
similarity or affinity. Special array processors are used by the HNC hardware,
and possibly be other systems such as IBM's Intelligent Miner Family ™ of
tools. Once useful associations are validated by the user, then appropriate
object aggregates can be configured to organize underlying data so that similar
associations are discovered, or additional information about the association is
acquired. This configuration can occur in near real time or as part of the
mining/discovery cycle.
Our model of implicit
knowledge is consistent with processing substructural features for associations
at one level and processing category objects and associations at another level.
The implied association model should be procedurally the same at either level -
but differ in the data processed. The use of a implicit (or tacit) knowledge
potential from bi-level computational argumentation is largely ignored in the
literatures. The exceptions are related to research programs in evolutionary
computing and connectionism.
Document Retrieval based on
Concept and Use Profiles
Use profiles can be user
profiles. A use profile can be maintained in the form of a category policy relative to one user, a
class of users, or a situation.
The voting procedure can be
used in describing (via summarization of meaning) aggregate objects such as
categories. This is a natural outcome since the relationship between
substructure and use properties of the category can be encoded. The voting
procedures can be structurally modified using linguistics, and situational
logics.
Example: a document is
placed into category 12. After a client reads this document it is routed into a
work flow queue where additional information is acquired about the situation
that caused the document. (The notion of causation is used non-literally to set
up the Mill's logic.) This information is used to refine a category policy for
all documents placed into category 12. User profiles are then developed to
simulate the routing habits of the client. These habits are seen in the context
of an environmental situation.
On Line Analytic Processing
(OLAP) is a paradigm that mines static or dynamic data sets for associations based
on co-occurrence distribution and affinities. These distributions form context
free grammars, the profiles of which can be used to establish appropriate
context, and refine affinity relationships. OLAP could also use evolutionary
computing or neural networks - but there are few public examples where this has
been done successfully.
Of course, co-occurrence and
simple implementations for affinity based on thesaurus will play a role in On
Line Analysis of Situations (OLAS). More has to be done to convert OLAP to
Decision Support Systems (DSS).
Mill's logic, as revealed
through the voting procedure, will mine the same data sets for associations
based on a more powerful paradigm. The affinities, now seen in information
warehousing, can be given qualities linked to a relationship variable between
data aggregations. The notion of Ultrastructure can and should be introduced
here; along with notions of interpretant, the notion of substructure and
control, and the notions of emergence and implicit memory seen in the voting
procedures.
Analog and distinctions
between Knowledge, Information and Data Warehousing
The language used in data
warehousing commercial literature has a few terms with analogs to the language
of Information and Knowledge Warehouses. These include the following:
Affinity, Aggregation, Associations, Classifiers,
Data Clustering, Decision, Discovery, Frames, Forecasting, Fuzzy Reasoning,
Index, Inference, Learning, Mining, Neural Network, Object, Query, Pattern
Identification, Reasoning, Rule, Summarization, Sequential Patterns,
Transaction
Summary
Information extraction
supports the spotting of topics in text or objects in images. In spite of the
advanced power of these methods, one of the open problems is in the
construction of automated processes.
Adopting a separation between mining and discovery is useful –
particularly if this separation is explained as part of the data warehousing
philosophy.
[1] Prueitt, Paul S. (1996c). Is Computation
Something New?, Proceedings of NIST Conference on Intelligent Systems: A
Semiotics Perspective. Session: Memory. Complexity and Control in Biological
and Artificial Systems.
[2] Prueitt, Paul S. (1997b). The Autonomous
Organization of Data through Semiotic Methods, in proceedings of the NIST
Intelligent Systems and Applied Semiotics conference, September 22-25.
[3] Prueitt, Paul S. (1997c). Grounding
Applied Semiotics in Neuropsychology and Open logic, in Proceedings of IEEE
Systems, Man and Cybernetics Conference, October 12-15, 1997, Orlando, Florida.
[4] Prueitt, Paul S. (1998a). A General
Framework for Computational Intelligence, accepted at 2ed World
Multiconferenece on Systemics, Cybernetics and Informatics, July 12-16 1998.
[5] Prueitt, Paul S. (1998b). An
Interpretation of the Logic of J. S. Mill, accepted at IEEE, Joint Conference
on the Science and Technology of Intelligent Systems, Sept. 14-17, 1998.
[6] Prueitt, Paul S. (1998). Measurement,
Categorization and Bi-level Computational Memory, under review.