Reflections made
during a meeting of the Peer 2 Peer Working Group
Northern Virginia
Jeffery Kay lead a discussion regarding where the Peer-2-Peer community has been and what the direction is when perceived from the technology point of view. The discussion centered around Intel’s sponsorship of a WC3 like “standards” group for Peer-2-Peer technology.
My take on the discussion was that the “industry” thinks of Peer-2-Peer as a means to sell more computer chips. Of course, the ultimate way to sale more chips is to enhance the development of technologies that create value while increasing the demand for Computer Processing Cycles (CPUs). One may suppose that the greatest unmeet demand for CPUs is the management of human knowledge capital.
During the presentations, I remarked that there is a large consumer community that had these unmeet needs. I suggested that we might to have a greater appreciation of the community needs, broadly considered by taking into consideration these unmeet needs. This suggestion takes us away from the technology issues and moves us towards the cultural and social issues. However, the great value of enhanced human knowledge capital is clearly within the Peer-2-Peer space.
As the discussion continued, I made some notes on some architectural issues – as related to extending the notion of context from a special notion of context established by the structured world of algorithms and networks. I reflected on how this structured notion might be “extended” to the every day notion of context.
Structured context exists due to the existence of invariance. An individual’s IP address is such invariance. Also, fundamental invariance is seen in the constants of the Newtonian laws on motion. Algorithmic invariance is a special case of structured invariance.
The notion of context is picked up in the next speaker’s presentation. His focus is primarily on the notion of algorithmic context. Rich Kilmer, co-founder and CTO of Roku Technologies, expressed a business strategy based on Peer-2-Peer capitalize on new technology that establishes algorithmic and structured context. The presentation is in line with proper capitalization efforts. In fact several of the companies represented in the working group, including 2nd Order and OntologyStream, see context technology is a core concern.
Here is an itemization of my notes taken during the two talks. The notes are the notes of a knowledge scientist who is receiving a fine tutorial on where Peer-2-Peer is in the marketplace.
Message patterns within transaction flows are of interest in establishing a representation of algorithmic context. Moreover, if the representational scheme is directed at capturing the structured context only then the problem of finding context has many interesting solution paths. These include Resource Description Format (RDF) and metadata, technologies highly funded by DARPA.
I recently developed an exercise focused on architectural issues related to the use of a knowledge management tool (from Acappella Software Inc.) in the Joint Intelligence Virtual Architecture.
http://www.bcngroup.org/area3/pprueitt/private/JIVA.htm
In the exercise, I describe an AS-IS model (in the spirit of the old Business Process Re-engineering techniques) that uses the RDF and metadata paradigm. However, it is our opinion that this paradigm will never extend beyond the acquisition of algorithmic and structured context. It is a mere matter of category. As the scholar Robert Rosen points out, there is a category error in thinking that structured and algorithmic context is fully representable of all natural contexts. Sometimes correspondences can be established and there will be utility, but it is not possible to predict when the correspondences will fail. The reason for this is simple. The world has a unstructured aspect that is not fully captured by formal models. These models depend on descriptive reduction to well defined and stationary structure.
Algorithmic context is context held completely within a formal model, even if the algorithms are part of distributed and so-called emergent computing. It can be far removed from the real world context that it is designed to reflect. To address the knowledge sciences issues, one must move from the representation of structured context and towards the representation of unstructured context.
In the opinion of many scholars, the utility of the RDF and metadata approach is limited. The utility of this approach is often supposed to be in the context of real world problems, not merely in the world of algorithms.
How do the concepts of knowledge management and knowledge sciences fit into various proposed architectural standards for Peer-2-Peer? Our TO-BE framework shows how.
After describing the AS-IS model, I developed a TO-BE framework that uses a simplified version of Russian applied semiotics and a software tool that facilitates the development and use of topic/question hierarchies.
The scholarship is outlined briefly in the short Preface of my on-line manuscript:
http://www.bcngroup.org/area3/pprueitt/kmbook/Preface.htm
and in the draft Chapters that follow this Preface.
Having set this background for the reader, I can perhaps ilustrate the new thoughts that occurred in my mind as I listened to the two presentations on Peer-2-Peer by Kilmer and Kay.
The RDF-type approach can be used to establish algorithmic context. In fact this might be the best use of these techniques. Lets see how such an approach might work.
Jeffery Kay expressed a model of Peer-2-Peer that is “three layer” with the following FTP-type stack for processes.
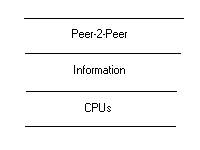
Figure 1: A three level architecture for Peer-2-Peer
This model of Peer-2-Peer is good for context routing and retrieval when the category of context is merely algorithmic. The kinds of algorithms referred to include: hidden Markov processes, Bayesian probabilities, latent semantic indexing, artificial neural networks, evolutionary computing, database transformation, and various scatter/gather algorithms. These algorithms and the consequences of their use are encapsulated in each Peer.
In Figure 1, Information is clearly regarded as a type of reversible data compression that is organized by the computer’s algorithms for the purpose of providing information for persons or perhaps other algorithms. It is interesting to note that data is derived from computers and distributed in a Peer-2-Peer layer. In this sense, the structure of the information is relevant to both the Peer-2-Peer layer and the CPU layer. So this architecture has merit.
However, algorithmic context is NOT sufficient to model any type of situational context as part of the natural world. It simply cannot reliably manufacture decision support processes and knowledge sharing experiences. The fundamental problem is that humans have “complex interiors”, and that one must make a category distinction between CPU’s doing algorithms and humans existing and thinking in a world that is perhaps more complex than algorithms lead us to imagine.
The general issues related to content evaluation is related to the issue of context evaluation. Content evaluation is addressed at:
http://www.bcngroup.org/area3/pprueitt/private/contentEvaluation.htm
As I was listening to the presentations I drew the following diagram:
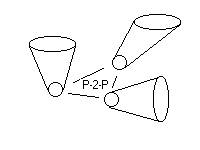
Figure 2: Peer-2-Peer with each Peer having a complex interior
The diagram places Information with the P-2-P layer, but an interpretive aspect occurs outside of the computer systems.
This leads me to draw the following diagram:

Figure 3: A second three level architecture for Peer-2-Peer
In this diagram, the Peer layer is seen to have the responsibility for mediating between the raw data processed by CPUs and the encoding of the invariance of these data into a token set, which we call structured information.
In Figure 3, Information is separated from the CPU layer by a Peer layer. In the case that the Peer layer is simply algorithmic, then we have algorithms interacting directly with CPU’s to produce a compression of the invariance of data into informational tokens. This sounds like data compression routines like Huffman, LZ and Rice. Using these routines, information can be organized to reflect relevant structured and algorithmic context, as well as to point to some aspects of unstructured context. The way information is used is thus subject, when appropriate, to the Acappella Innovation.
Unstructured information is most well know to us in the form of natural language. This fact is reflected in the formation of section / subsection / . . . / topic / question hierarchies by the Acappella software toolset. Linguistics and various assessment disciplines are also used to create a knowledge representation schema that is simply incomplete without the mental awareness of humans. It this sense, the Acappella Innovation is knowledge management without the limitations that are intrinsic to machine algorithms. A Power Point presentation of the Acappella Innovation is at:
http://www.ontologystream.com/EI/Solution_files/frame.htm
The diagram in the Figure 3 and the diagram in Figure 2 can be combined to produce an interesting cross product where two three-layer diagrams are sharing a common middle layer.
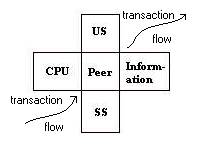
Figure 4: An architectural cross product accounts for the complex interiors
The Peer landscape sits between the CPUs and Information stores. The Peer landscape sits between the Sub-Structure (SS) and the Ultra-Structure (US). This configuration then allows the specification of tri-level routing and retrieval, with the lower level playing the role of memory (SS) and the upper level playing the role of anticipation (US). All four “layers’ are next-to and encapsulated by the Peer.
The memory layer can have the property of sharing within a layer of collective memory, but only as vetted by the Peer. This is consistant with the notion that the Peer may have a complex interior. The anticipation layer can be opened up to periodic revision (by an human awareness) to reflect the contingences of the environment. These contingences are called “affordance” in a well-defined literature that has become part of the basis of knowledge science.
http://www.bcngroup.org/admin/MUDs/eight.htm
In this way, the three layer {CPU, Peer, Information} architecture may provide the algorithmic context for services as required by Peer-2-Peer systems. These services include transaction and data mining services typical of Client-Server computer networks. This seemed to be the objective of the two presentations.
The tri-level architecture {sub-structure, middle world, ultra-structure} provides an architecture for knowledge science support of knowledge technologies.
In suggesting these new architectures, the world is turned on it head. The RDF type technologies are applied in a new area, and a more powerful stratified processing system is used to mediate the sharing of human knowledge. This is as the knowledge sciences would have it.