
eventChemistry ™ .
Development
Notes on Thematic Analysis
With
Tutorial and Design Document
by, Paul Prueitt, PhD
Founder, (1997) BCNGroup.org
President, OntologyStream
Inc.
Draft: December 26, 2001
Review of the work in progress
During December 2001, Don Mitchell and Paul Prueitt continued development of the OSI Browsers. Work on OSI Browsers addressed two difficult and significant problems
1) Event chemistry
2) Natural language processing
In addition to these two problems OSI has been working on a .NET Visual Basic and a C# version of the Root_KOS software.
Event and tokens
By early December, OSI had three small Visual Basic programs. These programs work together to create two levels of abstractions from an import file with enumerated description. The enumerated description must take the form of columns in a flat table where the values in the cells of the table are tokens. The tokens can be numbers used to reference types of events or names of events, or text characterizations of events. The assumption is that the tokens, individually and as a collection, have a functional load (a term used in linguistics for statistical/semantic measures of co-occurrence) that can be identified through emergent computing.
Events can be tied to the time that a natural or artificial event has occurred or the event can be a computer-process event such as natural language processing of ACSII text files. The parsing of a paragraph might be regarded as an event and the event data be placed into a single event record. Natural events are events that occur outside of the computer system. Artificial events are artificial only in the sense that they occur completely inside the computer system.
Review of the market strategy
Each of these three browsers (in theory) is derived from the same software template called the Root_KOS. Our purpose is to introduce knowledge operating system principles into the Root_KOS so that anyone using an OSI Browser can expect to have the same underlying functionality.
Our market strategy is to give these three browsers away, but not the code. However, the code for the Root_KOS is to be given away as a tutorial on how to convert Visual Basic to #C. This tutorial will be of interest to hundreds of developers. Our developing and giving away this tutorial will provide public exposure to the principles on which we are developing the OSI browsers. Academic relations have been established with a number of universities where basic and independent research of KOS design is being conducted.
Part 2: The
Tutorial
The following tutorial will mark current progress, help us move forward to next steps, and define issues to be addressed in January 2002.
Each of our tutorials have a specific zip file that can be used to see the:
1) Warehouse Browser with a specific Analytic Conjecture
2) The SLIP Technology Browser with a specific SLIP Framework
3) The Event Browser displaying initial random distribution’s of event atoms from Framework nodes
The zip file for this exercise is TAI.zip. (289 K zipped, including the three browsers and a data set.)
As we have done in previous tutorials, we will first review the data. After the review, we will delete the data and guide the user to produce similar results from whole cloth. But first we will review design issues.
Using FoxPro, we developed 5505 records from a natural language parse of the text of 312 Aesop fables. The records are created when one of a selected token from the fables is identified as being in one of the fables. So the “event” record has the form (token, name) where token is a word in a fable and the name is a numerical reference to one of the Aesop fable names. The numerical reference is used to make labeling in the event browser easier. In later versions of the event browser, a mouse-over will produce the full name and other metadata when appropriate.
The selection of the tokens is critical. We have talked about this in recent tutorials, for example in Section 2 of Creating and Visualizing a Citation Index: Exercise I.
From these early tutorials we see the beginning of concern
over the exact nature of and process for developing stratified machine ontology. We
cannot address all of these concerns at once.
Like the valances of
SLIP atoms, a outline model of these concerns can be made with a graph.
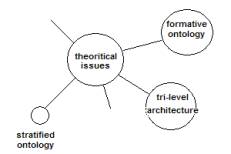
Figure 1: A semantic net depicting topics from SLIP foundations
There are two
critical issues that we will address now.
1) The nature of formative ontology
2) The nature of stratified ontology
Formative
ontology is machine ontology,
in the form of dictionaries, thesaurus, and formal ontology, that is
emergent. Two examples of formative
ontology are:
1) Categories in the SLIP framework (Figure 2a)
and
2) The compounds produced by event chemistry
(Figure 2b).
The SLIP Framework
is developed via interaction between human judgment and emergent computing
(scatter-gather on the circle).

a b
Figure 2: The two levels of abstraction (into ontology)
Fundamental theorems from a new field in set theory and
elementary number theory guide the work on SLIP Frameworks. Conceptual abstraction takes the form of
SLIP atoms, SLIP categories, and category primes. Formalism is available for transformation on these
abstractions. An example is the
scatter-gather and the eventChemistry.
Stratified
ontology is a machine
representation of knowledge that is organized into layers. The layers have no subsumption relationship
(see “On the Nature of Stratification” ) between the
layers. A subsumption relationship is a
part – whole relationship in the semantic sense. But meaning is destroyed when moving from one organizational level
to the level below. This removal of
meaningfulness is the key sign that a level of organization has shifted. For example the meaning of an individual in
a factory will shift depending on whether or not one is at the level of the
factory or at the level of the individual.
Any relationship existing between layers must be a relationship only in
the sense that
1) Some information structures will be developed
via emergent computing involving information structures from the level
immediately below.
2) Information structure should be usable to
generate reports (query retrieval) that provide an audit from information structure
to original data acquired and used in the formation of information
structure. An example is given by the
Technology Browser’s Report. In the
exercise below we will generate some Reports.
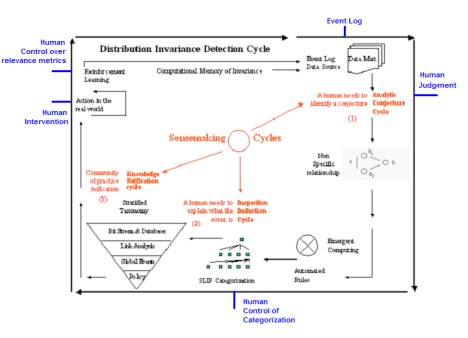
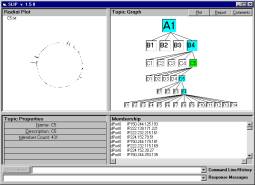
Figure 3:
SenseMaking Cycles
Taxonomy is a specific type of
ontology, where a strict (subsumption) relationship is imposed on the
relationship between tokens. Stratified
taxonomy constrains subsumption within levels.
Thus a stratified taxonomy is a stratified ontology. It is suggested that stratified taxonomy be
developed and used within a SenseMaking Framework as depicted in Figure 3.
In developing
ontology we can step through a process:
Step 1: Descriptively enumerate or parse-and-bin tokens to produce a
list of tokens.
Step 2: Filter out some of these tokens, add new tokens and refine the list.
Step 3: Make categorical relationships between tokens and token groups according to morphology, correlation analysis, and heuristics.
Step 4: Develop subsumption relationships (where and only where appropriate) and meaningful semantic linkage (using the ordered triple <a, r, b> where a and b are tokens and r is a semantic relationship.)
Step 5: Drive an organization of the tokens into a question-answering schema such as in Knowledge Foundations Mark 3 ontology encoder.
Step 6: Etc…
The current exercise shows one way to do Steps 1 and 2. Step 4 can be considered entailed in the Analytic Conjecture, the scatter-gather to the circle, and in eventChemistry. There are other ways of doing Step 4, one of these being Latent Semantic Indexing. Besides LSI, there exists perhaps 5 or 6 distinct methods are in the literature. Step 3 is mostly linguistic work.
Step 5 will be discussed in later tutorials.
The Parse-and-Bin
We will now look at Parse and Bin algorithms somewhat closely. A series of steps is made using FoxPro, steps not unlike those completed by workers in NLP systems hundreds (thousands) of times.
S.1: Clean and format hundreds or thousands (hundreds of thousands) of text files. They should all either start with a blank line or not, start with meta-data tagging or not, be delimited in a standard way, etc.
S.2: Bring each of these files into a position where the file can be parsed. Parsing will find matches between a selected token and a word (or phrase) in the text.
S.3: The Binning process is used to develop a list of all words occurring in the text collection. It is important to identify this list as an object, since this object will be reused in various ways.
S.4: Once the universe of tokens is identified then a subset of these tokens are identified either manually or using a machine dictionary. We may, for example, only want nouns to be used. This subset is called the set of Referent Tokens.

Figure 4: Production process for producing an event log using NLP
In Figure 4 we capture the sense of what can happen in the production of the list of tokens and the use of this list to produce the event log. The Natural Language Processing produces a selected token as being in a specific text file. One can then associate the selected token with the text file.
Now the question is about whether or not this selected token is in the Set of Referent Tokens. An In-memory Referential Information Base (I-RIB) technique is used here in order to reduce the software overhead and to make the membership assignment very fast. Of course, other slower methods exist for answering this question. The I-RIB technique was first developed for the scatter-gather process used by the Technology Browser. Anyone can obtain one of the Browsers and see this process occur.
Essentially what this does is to identify whether or not a selected token is contained in the set of referent tokens. If the selected token is contained in the set of referent tokens then we may regard the discovery, of this fact, as an event and report information out on the event log (See Figure 4.)
The event log then can be imported into the SLIP Warehouse Browser.
Time consuming comparison of a selected token to each element is not necessary IF one defines a natural order to the set of tokens in the referent set. If the tokens are all composed of ASCII characters then base 64 string-comparisons can be used. Such comparison is easy in any programming language. All we have to do is append a header to each token (to point back to a previous order in the datawh.txt file) and then write the set of tokens (with attached header) as a “line” of points, ordered by the ASCII order of the tokens. This simple concept enables a full spectrum of I-RIB techniques, some of which are proprietary in nature.
The speed of the scatter-gather capability in the SLIP technology Browser cannot be achieved using any other method. If fact we may conjecture here, without proof, that the I-RIB techniques used by the OSI Browser is the fasted possible search algorithm.
Let us see how the same technique is to be used in the NLP Browser.
Step 1: Descriptively enumerate or parse-and-bin tokens to produce a
list of tokens
Step 2: Filter out some of these tokens, add new tokens and refine the list
Step 1 is the standard means for producing an inverted index. Sample C# code for doing this will be made available January 15th, 2002. Step 2 involves either the use of a machine dictionary or a manual selection. We do not yet have a machine dictionary installed in the code for the NLP Browser, so FoxPro was used to assist in making a manual selection of all relevant verbs and nouns (from the list of all words that occur in the fables.)
After completing this manual task we counted 400 nouns and 381 verbs. This set of 781 tokens was used as the set of referent tokens.
These tokens need no header (why?) In the Technology Browser we needed to query back into a larger data structure, and so we needed the original record number from that larger data structure.
The Technology Browser’s report generator has tokens with headers. When I-RIB lines are used in this browser, the header is not used in ordering and comparison operations.
For us, the situation is a bit simpler. We need only do the following:
1) Look through the set of referent tokens to find the one that has maximum size in characters. Designate this integer as ‘tokenLength’.
2) Pad to the left each token with sufficient blank spaces, space(n), with n the minimal integer so that length(token + pad) = tokenLength.
3) Reserve a section of machine RAM of length tokenLength * 781.
4) Order the set of referent tokens by ASCII order and write the tokens in this order into this section of RAM.
Now each question regarding membership can be settled in less than 10 comparisons. Each comparison involves the selected token and one of the padded elements of the set of referent tokens. In between these fast comparisons we move to the left or the right on the line to the midpoint of that part of the line that remains to inspect. Since 2^10 > 781, there are less then 10 of these fast cycles.
We call the ordered set of referent tokens the Referential Line, or Line for short.
So each word of each fable can be compared with the Line in a few machine cycles. The entire collection of 312 fables can be parsed in under a second. Each time the selected token is found in the Line then an event record is produced. This event log is formatted in the form needed by the Warehouse Browser.

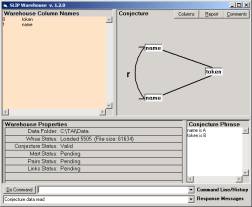
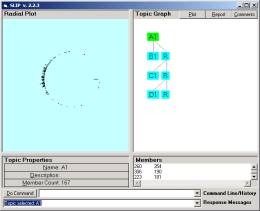
Figure 5: Atoms from one of the SLIP categories
In Figure 5 we show the event atoms for a category derived from a quick study of the functional loads of the Aesop collection. As in Latent Semantic Indexing (LSI), we focus on a relationship between the membership of an “internal token” and a profile of the larger group. In this case the token is a member of the Line and the larger group is the collection of individual fables.
So how is SLIP different from LSI? In SLIP event atoms are an abstraction that initially sets aside frequency and looks only at co-occurrence. This can be done with LSI also. However, the Warehouse Browser (Figure 6a) facilitates control over the focus of co-occurrence analysis. So access to the technology by individuals who are not specialists in text understanding theory and techniques is a difference. We will see that a more profound difference is related to the SenseMaking Cycle and the additional layers of abstraction possible using formative ontology.
Both LSI and SLIP clustering process are distributed. A more complete comparison should be made, but has not been made as yet. However, it appears fair to say that LSI is based on statistical methods and methods from linear algebra (specifically a matrix decomposition technique), whereas SLIP is based on category theory and emergent computing.
The validity of either approach should be verifiable using the other system to create a clustering of the elements of the larger collection. The functional load (again a term in linguistics) between tokens in the context of the larger units can be partially discovered either way. Functional load (the ease of elementary things to combine and express semantics) is what both SLIP and LSI is looking for. Functional load weakly controls the way language is used in speech, and in authoring fables.
Functional load is more strongly controlling of the way hackers can attack computer system exposures and vulnerabilities. The reason why the functional load is controlling is related to the means through which hackers (or fable writers) must act. Some experiments have been made on the relative stability of the “distribution of limiting distributions” for computer incident management and intrusion detection data when compared to the distribution of limiting distributions in application to text collections.
a
b
Figure 6: A study of co-occurrence of tokens in fables
Perhaps the previous exercises on computer incident management and intrusion detection data will convince the reader that the co-occurrence of tokens in fables is just one type of Analytic Conjecture.
We seem to be limited here only by the imagination of the expert.
<Incomplete…..>
Appendix for Figure 5