Cyber
Defense Knowledge Base
Obtaining Informational Transparency with Selective Attention
Distributed at
Congressional Briefing on CyberSecurity
Sponsored by the Forum on Technology &
Innovation
Thursday, February 14 12:15 - 2:00 p.m., Room SC-5, U.S. Capitol
What is the break-through?
This
system is different from ALL other visualization systems.
1)
A new methodology called eventChemistry
visualizes event types as abstractions.
2)
The event types are developed
from existing firewall and Intrusion Detection System audit log files, but
reside in a separate system.
3)
The event-type knowledge base
is very small and the technology is not complicated.
4)
The abstractions have 100%
precise recall of all log events that were involved in developing the
abstraction.
5)
The abstractions provide a
system of icons based on actual eventMaps.
6)
The iconic system is a visual
language that assists the selective attention of humans.
7)
The visual language is a
control language for access to various parts of the knowledge base.
8)
The abstractions can be
automatically converted into algorithmic rule bases so that fast control of one,
or many, Intrusion Detection Systems are enabled from event knowledge.
9)
The abstractions serve as top
down expectancy and thus as predictive inference when incomplete and partially
incorrect data is being examined.
10) The abstractions can be used to extract similar events from data
sets different from the data set in which the event was first discovered.
11) The abstractions can be linked into game theory to provide simulation
of cyber war strategies.
12) Knowledge sharing within various communities is enabled by a
common standard.
Dr. Paul S. Prueitt, Founder, OntologyStream
Inc
Summary of Possibilities
February 6, 2002
(Revised from a December 5th,
2001 version)
Overview
In response to a request from industry, we reviewed the research and technical literature on intrusion technologies and incident management. This review involved discussions and correspondence with leading academics in information assurance, artificial intelligence, knowledge engineering and process theory. The written literature on intrusion and incident detection, hacking and cyber war was read.
The current incident management systems are not predictive and not fully automated. Industry Management recognizes this, as does the Federal government and commercial Computer Emergency Response Team (CERT) communities.
An analysis as to why incident management is not predictive was developed and presented to the industry client. The purpose of this analytic work was to advise the client about technological possibilities for automating key aspects of incident management. Our work produced prototyped software that deployed various techniques from data mining and artificial intelligence.
In November, the client declined to continue work. However, during the month of December 2001 and to the present time, OSI continued work on the fundamental technology and its implementation.
OSI is currently looking for a corporate partner to mange our technology implementation process model.
We have extensive background in technical areas that are predictive and which automate the acquisition of information from databases. A new and original approach was conceived for the visualization of event types and for the preservation and reuse of informational structures in a compact knowledge base. Software has been developed and evaluated by independent third parties.
We continue to develop a system that could become an independent defense system against cyber war and computer hacking.
1: On the data management system
The SLIP Data Management System is a member of a new class of data management systems called Referential Information Bases (or RIBs). The SLIP Data Management System is not a standard relational database and does not run on third party software. It is self-contained and has a small footprint. The RIB based SLIP architecture uses files compressed into folder structures and in-memory file mapping techniques to eliminate the dependency on an enterprise DBMS.
The acronym “SLIP” stands for “Shallow Link analysis, Iterated scatter-gather, and Parcelation”. Each of these terms is technical in nature and each term has a small number of supporting RIB based algorithms. The RIB architecture is advanced, simple and very powerful. Part of the purpose of this technical note is to indicate why the RIB processes are fast, and why their existence alters what can be done. A minimal data structure is created in-memory and algorithms are applied to data aggregation processes.
The RIB systems are under develop by several independent groups around the world, including OSI, a group at Swinburne University of Technology in Australia, a group at the University of Connecticut, and a company in Washington State.
Prueitt is one of the founders of the approach in computer science on which RIBs are built, and has applied several of the fundamental algorithms and concepts within the prototype software.
Groups around the world are adopting new paradigms centered on in-memory data management systems. The paradigm applies to data warehouse / data mining systems and to neural network and genetic algorithm system. This paradigm provides a great deal of independency from enterprise software systems such as RDMS. In particular the SLIP Technology has its own correlation and categorical algorithms. Associative memories using the RIB system are under development as an internal project at OSI.
However the independence of the software from other software is not the only reason why there is interest in the new data mining data warehouse systems. Data mining and data warehouse systems require a great deal of speed if the system is to be real time and interactive. The RIBs change the way in which theses processes are computed so that we get the same results but in a small fraction of the time.
2: Incident and Intrusion Management Systems
Because the Incident Management and Intrusion Detection System (IMIDS) task in NOT complex, the RIB based stratified knowledge base is potentially a full solution to outstanding problems in pattern recognition and event detection.
This potential remains a conjecture until SLIP Technology is
first field-tested. However, some
private field tests are being developed using private firewall data
and data from a UNIX web server.
Moreover, work on the use of this
technology for autonomously guessing the meaning of terms within a text
collection is highly relevant to the development of the stratified
knowledge base of event types. The
notion of linguistic
functional load and the functional load of pattern of events is developed
in private research and in a few public documents.
In a typical Intrusion Detection Systems (IDS) the standard relational data mode is used to store remote audit feeds from various customers. Various DBMS tools are used to perform analysis; correlation and data visualization in support of
1) vulnerability assessment
2) identifying hacker and cyber warfare activity
3) forensic analysis and
4) policy determination
The basic components of a combined Intrusion Detection and Incident Management System (IDIMS) follows the generic architecture proposed for all IDS systems by Amoroso and considered as part of the Common Intrusion Detection Framework (CIDF), with the exception that informational response to Incident Tickets are seen as emergent from IDS audit logs.
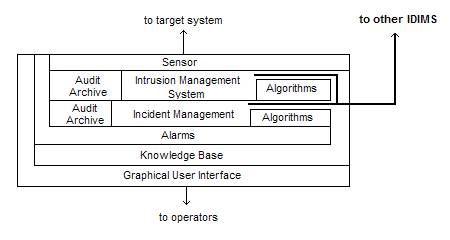
Figure 1: Architecture for Incident and Intrusion Management
An Incident Ticket is generally opened due to a phone call or e-mail. In most cases, the Incident Ticket is opened due to human intervention. However, increasing technical capability provides automation to Incident Response in the form of algorithmic alarms.
After the Incident Ticket is opened a series of steps are recommended.
In the book "Incident Response" by
van Wyk and Forno (2001, O’Reilly) the response cycle is composed of
Detection,
Assessment,
Damage control,
Damage reversal
and
Lessons learned.
This composition is similar to other intrusion detection and incident response process models that break down the workflow. The processes are compartmentalized and responsibilities isolated
The workflow starts with a determination of the nature of information. In some cases the information comes in the form of a request for information. In other cases the information is sorted into categories and moved to other stations depending on the informational category. The process model is very much dependant on organizational structure in client communities.
The first phase of the SLIP technology design and development has been developed to provide an enterprise wide event detection capability where the input is any log file.
3: SLIP Warehouse Browser
The basic methods for intrusion detection is, and will continue to be, audit trail analysis and on the fly processing techniques. SLIP is best characterized as an audit trail process method (see Figure 2). The CylantSecure system developed by Dr. John Munson (University of Idaho) is an on-the-fly system (see Figure 3) that attempts to stop intrusions from occurring.
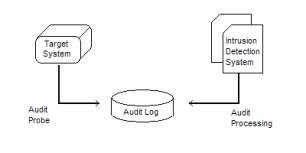
Figure 2: High-level depiction of audit trail processes method (from Amoroso. 1999)
Audit log data is gathered together to provide forensic evidence and to repair and otherwise limit the damage done during an intrusion. However, visualization software can be used to view patterns across an audit log containing tens of thousands or records. The SLIP is developed to complement and supplement this type of global analysis of events.
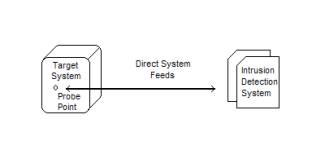
Figure 3: High-level depiction of on-the-fly processes method (from Amoroso. 1999)
The current SLIP Warehouse Browser has a simple nature. The technology is simplified to address only audit trail analysis and transforms on the data from a standard event log. The technology is also being applied to other task domains such as found in bio-informatics; in particular a long-standing BCNGroup project on the recognition of structural invariance in EEG analysis is re-surfacing. However, EEG analysis is considered far more difficult that intrusion log data.
The BCNGroup is a not for profit science foundation established in 1997 by Drs Edward Finn, Arthur Murray and Paul Prueitt.
4: Invariance analysis with SLIP
Aside from some EEG analysis, SLIP is currently applied to remote audit feed analysis for computer security purposes and to studies on linguistic functional load. Specifically, emergent computing and correlation techniques are applied to the records of an event log.
Computer security event log is often stored and maintained in a flat table having between 8 and 20 columns. Many of the event logs contain 50 or even 100 thousand records. Audit feed event logs may have a million records.
In the simplest terms we want to reveal the technical means that supports the Browser’s behaviors. The behavior is expressed through a state/gesture based scripting language and nested event loop controller. Our recent work has been on the development of a voice enabled gesture control system for manipulating and interacting with machine ontology. The control system is called a Knowledge Operating System or KOS.
SLIP organizes invariance in a data source into categories and suggests formal relationships between these categories. As the domain experts review these categories and their relationships, the expert may create annotations and even configure the relational linkage between categories in order to account for missing or conjectured information. The domain expert also has control over which data source is accepted as input.
Invariance is formally something that occurs more than one time. Clearly there are many scales of invariance and a lot of invariance in each scale. This is true even in the artificial world of Internet and financial transactions.
For example, ACSII letters each occur a lot, for example, and common patterns of ACSII characters allow for automated full text analysis. Internet search attests to the value of algorithmic analysis of words patterns in text.
The informed introduction of case grammar and modeling algorithms can increase the value of plain vanilla ACSII character based invariance analysis. These algorithms are important to computational natural language analysis. The invariance that SLIP exploits is one that is revealed in a pairwise link analysis called the “SLIP Analytic Conjecture”. This invariance is quite a bit simpler than case grammar. SLIP is simpler to work with.
The notion of an atom is the key abstraction in the automated analysis of invariance in Audit Logs. The atoms are the equivalence class of all same values of the contents of the cells in a column. These atoms are then used to form event chemistry. The work product from the Event and Technology Browsers is acquired by the Mark 3 class knowledge base system.
5: RIB arithmetic
Let us look at the SLIP Analytic Conjecture a bit closer. The audit feed is always composed of records and each of these records is constrained to have a specific number of cells. Each cell has a defined name and a value. When we have more than one record, we often think of the cells of the same defined name as being a column.
In Figure 4 we show a screen capture of the Excel spreadsheet application. Cell A-1 is indicated and the value “cell value” has been typed into that cell. Columns A, B, C and D are visible, as are records that are numbered, 1, 2, 3, 4, 5, and 6. Sometimes records are called rows.
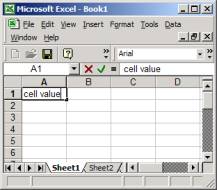
Figure 4: Microsoft Excel spread sheet
The naming convention “rows and columns” conceptual ties together the cells of a 2-dimensional spreadsheet with the cells of a 2-dimensional array. An array is a mathematical object that is like the spreadsheet. An array is composed of cells organized into columns and rows. The simplest array is one that has one column.
A foundational concept in RIB is the ordered column. We will call an ordered column a “RIB line”, to remind the reader of the ordering properties that come with geometrical lines. In-memory mapping of an ordered column allows a type of pointer arithmetic and object transformation such as a Fourier transformation.
The natural order of the points on a line (as in plane geometry) has been used in science for at least 25 centuries. During the last 2 centuries the theory of partial and total ordering, part of modern mathematical topology, has established some well understood formalism regarding linear order, lattices, gaskets and rough sets (to name a few of the formal constructs). Topology is the study of formal notion of nearness and neighborhood.
Topological constructs have not been extensively used in data aggregation. Perhaps this is due to the level of abstraction.
A combination of computer science, combinatory and topological logic, artificial neural networks, theoretical immunology, and mathematical topology has established a radical simplification in the sort and search algorithms necessary for data aggregation. The result is speed, and with this speed we are able to allow real time interaction with a sign system based on data invariance and transformation of data invariance.
The information technology community may now consider some rather startling facts. Let is look at one of these facts. Suppose we have a collection, C, of one million numbers randomly selected from the set of integers less than one billon. Now select one more integer, n, randomly between 1 and 1,000,000,000. One of the SLIP algorithms will determine if n is an element of C in 31 integers comparisons.
How is this possible? The answer is very simple to understand once perceived. The concept of a RIB line is derived directly from a concept developed in mathematical topology. As introductory graduate texts in mathematical topology show, a sequence of dyatic rationals can be used to partition a line in a certain nice way. This is sometimes called the Cantor set. But the concept has not often been applied to the search space problem, and for a good reason. However this reason can be side stepped using a change in number base. Hint: the base should be the same as the number of letter atoms found across the set of all tokens.
If we are using upper and lower letters plus the base 10 digits then this base is 62. Using this base, the text in databases has a natural order where all same values are put together. This order serves as a means to memory map data. One-pass transformations then compress this data categorically into atoms and combinatorially into pairwise metrics.
With arbitrary data columns represented as RIB lines, then the same search and sort algorithms available for numeric columns are universally available. Programs can then treat the entire collection of text or numeric data elements as a single object.
The SLIP Technology Browser uses a generalization of a dyatic partition sequence to find out if a specific string of length, of say 20 ASCII characters, is within a string of several million ASCII characters. This search algorithm is completed around a million times in order to produce the cluster process in the SLIP Technology Browser. Each iteration takes less than 31 base 62 numeric comparisons. The entire cluster process now takes a few seconds. The same search process takes over 4 hours using the FoxPro Rushmore indexing technology.
The SLIP Warehouse Browser works with ASCII files as input. The data is read into four types of in-memory data structures;
1) objects
2) arrays
3) lines
4) mapped files
Objects are typical Visual Basic, Java or C++ type objects. Objects have an interface that defined how the objects’ methods and private data are accessed and manipulated by messages sent between objects.
Arrays, lines and mapped files are not objects because these constructs have no interface and no internal methods or data.
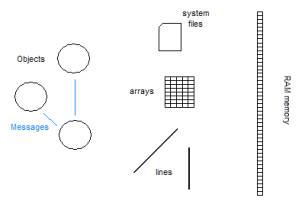
Figure 5: The basic elements of the SLIP data structures and algorithms
In the next section, we will look at the process model that takes audit log information and transforms this information into the data elements that are necessary to the SLIP Technology Browser.
6: The Process Model for the Warehouse Browser
The Browsers themselves are very simple stand-alone executables originally developed in FoxPro and then entirely ported to a RIB architecture written with minimal Visual Basic. The Warehouse Browser is under 200K in size. The Technology Browser is under 400K in size. There is no installation process as the code runs without any custom VB DLL.
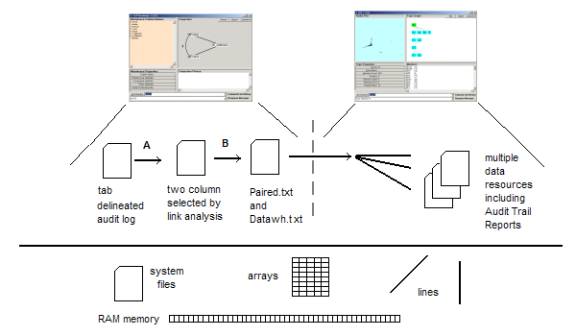
Figure 6: The Process Model
Figure 6 shows that the SLIP software is a complete system with an interface, a data layer and a physical layer.
The Warehouse Process Model takes a tab delineated Audit Log and allows the user to select any two of the columns for a link analysis. The two columns are written out to a file called Mart.txt. A special algorithm completes the link analysis in a few seconds and produces an ASCII text file, called Paired.txt, consisting of a single column of paired values. The paired values are both from the second column. The first column in the Mart.txt is required to establish the pairing relationship.
Example: Mary talks to Don and James talks to Don. Mary and James would both be second column values and Don would be the first column value. Mary and James are paired because of the possible relationship.
The special algorithm simply makes a list of all values that occur in the b column and then makes a delimitated string with all “a” values that occur in a record where the b column value is Mary (for example). This string is then converted into all possible pairs of “a” column values, and written out to the Paired.txt. The relationship to the “b” value is lost as the algorithm moves from one “b” value to the next.
This process of abstraction produces atoms that have link potential represented as in Figure 7. The existence of a relationship, or not, is the only information used by the clustering process.
Recall that any two columns can be used to develop an Analytic Conjecture. Switching the two columns makes a complementary relationship. This complementary relationship is not used in the atom clustering process. A different use has been found. The complementary information specifies the set of relationships that a single atom may have to any other atom.
When the clustering process is completed, then the set of atomic relationships can be used to represent the cluster in an event graph. (See Figure 7.)
The set of atomic relationships has been made part of the SLIP atom object. The complementary relationship to the Analytic Conjecture is used to compute this set. The atom object is available as part of the SLIP Technology Browser.
Table 1
<atom = 3128,
count =10>
<2417 1163 46819 41299 4511 1706 1711 1708 10246 1305 >
<atom = 3130,
count =2>
<1024 2403 >
<atom = 161,
count =4>
<1025 1024 1393 10010 >
<atom = 520,
count =1>
<1024 >
<atom = 568,
count =1>
<2417 >
<atom = 80,
count =103>
<37604 37625 3270 62556 62577 62584 2415 3917 62781 62978 63008 63031 63149 61241 64244 48627 1126 12073 63557 63603 63605 36319 63624 63633 63653 63663 1982 63753 2215 4074 63658 63669 2370 1144 1303 63925 1415 1313 1315 1321 1323 1325 1327 64098 64013 1336 1338 4743 3394 64577 64627 64629 13687 65051 3065 61357 61649 56444 4676 61991 62231 62237 62353 62388 2855 2858 1509 3955 62523 2861 62609 62783 3936 1095 4537 4539 63227 4487 1840 34084 1673 62851 63253 1391 4427 27132 3426 1224 42546 1125 3016 10769 10915 22886 4915 10711 6980 3993 1098 1099 33718 2639 1186 >
The SLIP atom is a data invariant across the values in the column of the SLIP Analytic Conjecture. Each specific actual pair of SLIP atoms has a “b” value that links the two parts of the pair. The “b” values for each “a” value are also treated as a abstract equivalence relationship. The equivalence relationships are links for each atom.
A “show atom” command and a “show graph” command now
(February 5, 2002) allows the user to see the types of graph and graph
components that are hand drawn in Figure 7 (December 5, 2001).
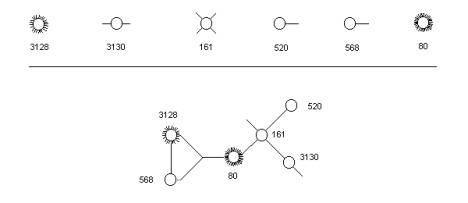
Figure 7: The
specification of both atoms and event graphs
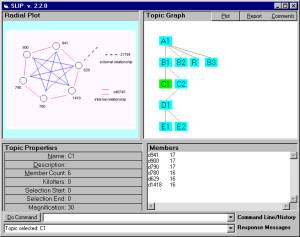
Figure 8: A mock up of the display of event graph in the Technology Browser
OSI’s work on the Event Browser continues to be an OSI
Internal R&D project, solely funded by OSI.
As part of his work for OSI, Don Mitchell developed a software application called Root KOS. Each of the SLIP Browsers were initially cloned from Root KOS and then evolved to have a specific functionality. A small finite state controller is built into Root KOS to allow voice-activated commands. IN the future (March 2002) we hope to develop an interface to a Knowledge Base of the Mark 3 class from Knowledge Foundations Inc.
The SLIP Technology Browser was the first to be created. The SLIP Warehouse was created to establish the files needed by the Technology Browser.
The Event Browser will be the third offspring from Root KOS. A management tool called “Splitter” is a fourth offspring. This tool manages large input files.
The simple functionality of the SLIP Warehouse facilitates highly interactive data aggregation without a huge technology overhead.
When our enterprise software develops then we will address issues related to the sharing of knowledge within a secure community.
This
system is different from all other visualization systems in the following ways:
13) EventChemistry
visualizes mental abstractions and therefore the knowledge base can be very
small.
14) The
abstractions have 100% precise recall of all log events involved in developing
the abstraction
15) The
abstractions provide a visual language (eventMaps) for the control of access to
various parts of the knowledge base.
16) The
abstractions can be automatically converted into rule bases so that fast
control of one, or many, Intrusion Detection Systems are enabled from the
abstract event knowledge.
17) The
abstractions serve as top down expectancy and thus as predictive inference when
incomplete and partially incorrect data is being examined.
18) The
abstractions can be used to extract similar events from data sets different
from the data set in which the event was first discovered.
19) The
abstractions can be linked into game theory to provide simulation of cyber war
strategies.
And a few other things.
Section 7: National Defense System against Cyber
War
National Defense System against Cyber War goes beyond an often demonstrably failed process of Intrusion Detection and Response and deploys a structured and stratified taxonomy across the governmental Computer Emergancy Response Team (CERT) centers.
Each of four levels of the taxonomy has human terminology evolution processes, in conjunction with human communities of practice.
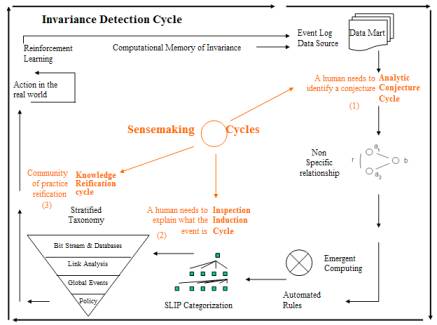
Figure 8: Sense making architecture for the Cyber Defense System
The bottom layer of this layered taxonomy is an open semiotic system depending on invariance types (categories) produced from the data aggregation of the Internet traffic at selected points within the Internet systems. The second layer is an intrusion event level that is responsive to the already deployed infrastructure of Intrusion Detection Systems (IDSs) and to the visualization of intrusion event patterns at the third level. The third level is a knowledge management system having knowledge propagation and a knowledge base system developed based on Peircean logics (cognitive graphs) that have a formative and thus situational aspect. The fourth level is a machine representation of the compliance models produced by policy makers.
The current version of the SLIP Warehouse Browser produces two ASCII texts called Paired.txt and Datawh.txt. Datawh.txt is simply the original audit log data written in a standardized tab delimited form and having a small XML header for metadata.
In the next section we will make a few comments about the RIB based data-warehouse data-mining paradigm and the issue of interoperability.
8: On the Stratified Event Knowledge base
Edward Amoroso, Information Security Center of AT&T Laboratories states “I believe that a major focus in intrusion detection in the future will be vast data warehouses that are created for security attack mining” {Page 12, Intrusion Detection (1999)}. In his 1999 book he outlines an architectural schema that was instrumental the DARPA’s Common Intrusion Detection Framework (CIDF).
Of course, the break through promised by eventChemistry is that this vast data warehouse is “compressed” into very small set of period tables and the OSI Knowledge Operating System (KOS). These tables are composed of abstractions, just like the periodic table used in physical chemistry. The foundational theory for this type of knowledge base is primary derived form Soviet era applied semiotics and Prueitt’s work in cognitive neurodynamics.
The process architecture for the SLIP warehouse is consistent with the CIDF principle that audit log processing should result in the development of data warehouses that have simple and interchangeable formats. In our case, the processing will always produce a tab delineated ACSII file with XML header for metadata. These files can be e-mailed or otherwise transmitted from one SLIP warehouse to another.
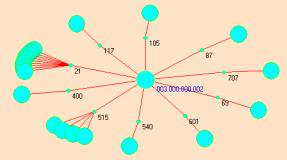
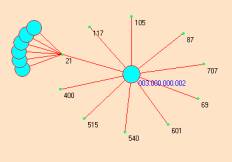
Figure 9: An early complex eventMap
Unlike Oracle data files or Sybase data files, the SLIP files are readable, and editable, using any text processor. In all cases, the SLIP Browsers will be sufficient for creating, opening, modifying, and archiving these resource files.
The SLIP technology has some of a category of RIB sort and search algorithms. These are partially public domain and partially proprietary. They are perhaps provably optimal in terms of speed. These algorithms are being further refined and are to be applied to full text data mining and bio-informatics by Dr. Cameron Jones, School of Mathematical Sciences at Swinburne University of Technology, and his PhD students. This is a long-term effort by dedicated scientists. Patent applications are being developed.
Just a
comment will be made about our innovative work. The application of the
principles of SLIP is applied to full text (unstructured) data using an n-gram
algorithm.
The
n-gram is a window of a fixed length (generally n = 7) that is moved over the
text strings one letter at a time.
Generally the contents of the window are binned as in an inverted index
used in text spell checking. The bins are then the first order of
invariance. We then use an abstraction
where one regards the occurrence of the string has categorically the same as
the bin that the string is a member of.
The bin
is made a proper representative of every occurrence of that string in the
text. Link analysis is done on this set
of abstractions. The set of
abstractions of "reoccurring strings" in the first order invariance
is generally around 1500 - 2000 for a narrowly defined text corpus. The link analysis in the Intrusion Detection
SLIP Browser uses only two columns, whereas the n-gram analysis produces 1500-2000
columns. However there are two ways to
address this:
a) Use the letters as a measure of nearness and cluster the
n-grams into categories as is now done in the standard n-gram technique.
b) Perform a more complex link analysis related to Markov processing and emergent case grammars (as validated by linguistic analysis)
However, this work is left primarily to the Swinburne group. The reference to this work is made here to indicate that various groups around the world are developing a new RIB based paradigm for data aggregation processes. Various vertical markets exists outside the cyber war domain. However, some unpublished work on the use of the technique for organizing human knowledge about the use of hacker tools in the Internet.
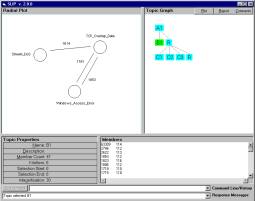
Figure 10: A simple event graph
Specific to Incident Management and Intrusion Detection Systems (IMIDS), one might consider a similar approach that would first take n-grams over the concatenation of the records of selected audit feed logs. However the ASCII character distance between IP addresses is not semantic bearing and would be complicated and confusing to most users. The application of a Neural Network associative memory also does not produce a clear use paradigm since the user does not participate in the formative process.
The SLIP Technology sidesteps these issues. The user develops the SLIP Analytic Conjecture using the SLIP Warehouse Browser. Once simple link analysis is defined the Warehouse Browser produces the two files needed by the Technology Browser. The user then is allowed to develop the categories by visual inspection. One result of this work is the production of event graphs.
The KOS and OSI stratified knowledge base of event types places these graphs (visualization of abstract event types) into a stratified Knowledge management (senseMaking) system.
SLIP Technology Browser Exercise III (dated November 19th, 2001) explores the development of the event graphs.
Another result of the user’s work with the
Technology Browser is the production of Reports about the nature of the atoms
in a cluster. These Reports are a
subset of the original Audit Log.
As SLIP Warehouse Browser Exercise I shows, these Reports drill down into the Audit Log and identifies only those Audit Log records that are involved in both
1) A match to the values of one of the atoms in the category, and
2) A chaining relationship, involving non-specific linkage, within the category
The chaining relationship is derived from the non-specific relationship defined by the Analytic Conjecture AND the clustering process, and should be indicating a real but distributed event.